[NVIDIA Nemotron Hackathon] Grand Prize Among 20 Teams: Behind Two Sleepless Days

Hancheol Park, Ph. D.
AI Research Engineer, NetsPresso Tech, Nota AI

Geonmin Kim, Ph. D.
AI Research Engineer, NetsPresso Tech, Nota AI

Geonho Lee
Edge AI Engineer Intern, NetsPresso Tech, Nota AI

Jaehoon Lee
Technical Content Manager, Nota AI
Prologue: The Three Who Took the Stage Last

Figure 1. Team Nota AI after winning Grand Prize at the NVIDIA Nemotron Hackathon
On April 21–22, Nota AI took home both the Grand Prize and First Place in Track C at "Nemotron Developer Days Seoul 2026," NVIDIA's first hackathon held in Korea.
As you'd expect from a hackathon hosted directly by NVIDIA, the lineup of contenders was a strong one. With Naver, which took First Place in Track A, and most of the leading Korean companies known for their AI work all in the room, the win carried that much more weight.
This story belongs to the three who took the stage last after a no-sleep two-day sprint: Hancheol Park (referred to as "Hancheol" below), Geonmin Kim ("Geonmin"), and Geonho Lee ("Geonho"). In this interview, we'll trace those 48 hours from a slightly different angle.
Part 1. The Starting Line: Data, Not Algorithms
Q. The name "Nemotron" might still be unfamiliar to many readers. Could you start by explaining what the "NVIDIA Nemotron Hackathon" actually is?
Hancheol: NVIDIA Nemotron is a family of open models, datasets, and techniques released by NVIDIA. What sets it apart is that NVIDIA shares not only the model weights but also the training datasets and the methodologies used. The reasoning models come in three sizes: Nano, Super, and Ultra. NVIDIA also provides a range of tools to put these models to use, such as agent-building tools and synthetic data generation tools.
The hackathon offered three themed tracks:
Track A: Creative Agentic Systems (building AI agents to solve real-world problems)
Track B: Domain-Specific Nemotron Models (fine-tuning and reinforcement learning of the model)
Track C: Nemotron for Synthetic Data Generation (SDG), focused on designing synthetic data pipelines for high-quality datasets
Different as the tracks were, the common thread was clear. Using the Nemotron model as the agent's brain to deliver strong results was at the core of every track.
Q. What drew you specifically to Track C among the three?
Hancheol: For some time, we'd been thinking about quantization optimization from a data perspective rather than an algorithmic one. The industry mainstream so far has advanced by refining algorithms, but we kept observing that even with the same model, results vary considerably depending on which data you use for calibration. We saw the hackathon as a good chance to validate that hypothesis.
Q. How did the team come together?
Hancheol: Hackathons are short on time, so we wanted clear roles from the start. Geonho and I worked on the proposal and shaped the idea together from the beginning, and roles fell into place naturally during that stage.
I led the team, coordinating workflow on-site and taking responsibility for the slide deck and the presentation itself. Geonho took on the core methodology implementation, along with the experiments and evaluation. Geonmin handled methodology implementation on-site, together with the demo and repository standardization.
That was the broad division, but it wasn't a hard split. Whenever we hit a wall, all of us jumped in to work it out together.
Part 2. Two Days, No Sleep: A Perfect Plan and an Imperfect Reality

Figure 2. D-Camp Mapo workspace, mid-sprint over the no-sleep two days
Q. Now let's get into what actually happened on-site. The idea the three of you came up with was "synthetic data generation specialized for MoE quantization." To help readers get a sense of it, could you walk us through the core idea?
Hancheol: Mixture-of-Experts (MoE) is an architecture designed to make large language models (LLMs) more efficient. Inside an MoE model, there are many "experts," and only a subset of them is activated to process any given input. The catch is that the activation frequency across experts is heavily skewed, almost like a Pareto distribution. Some experts get activated very often, while others rarely fire.
The real problem surfaces after quantization. Quantization lowers precision and limits the numerical information you can represent. Because you have to choose which values to keep and which to drop, you need a clear picture of which experts are being activated. For frequently activated experts, the statistics accumulate enough to make that call; for rarely activated ones, the judgment becomes uncertain. And you can't simply throw an unlimited amount of calibration data at the problem either.
Geonmin: That's where we started: "What if we design the calibration data so that all experts activate evenly? Wouldn't that reduce quantization error?" As an analogy: a familiar combination like "Want a cup of coffee?" only triggers the same frequently activated experts repeatedly, but a strange combination like "Add a spoonful of topology to my coffee" fires up experts that don't normally get activated. So our first axis was to deliberately inject these unusual combinations into the calibration data. Geonho added a second axis on top of that.
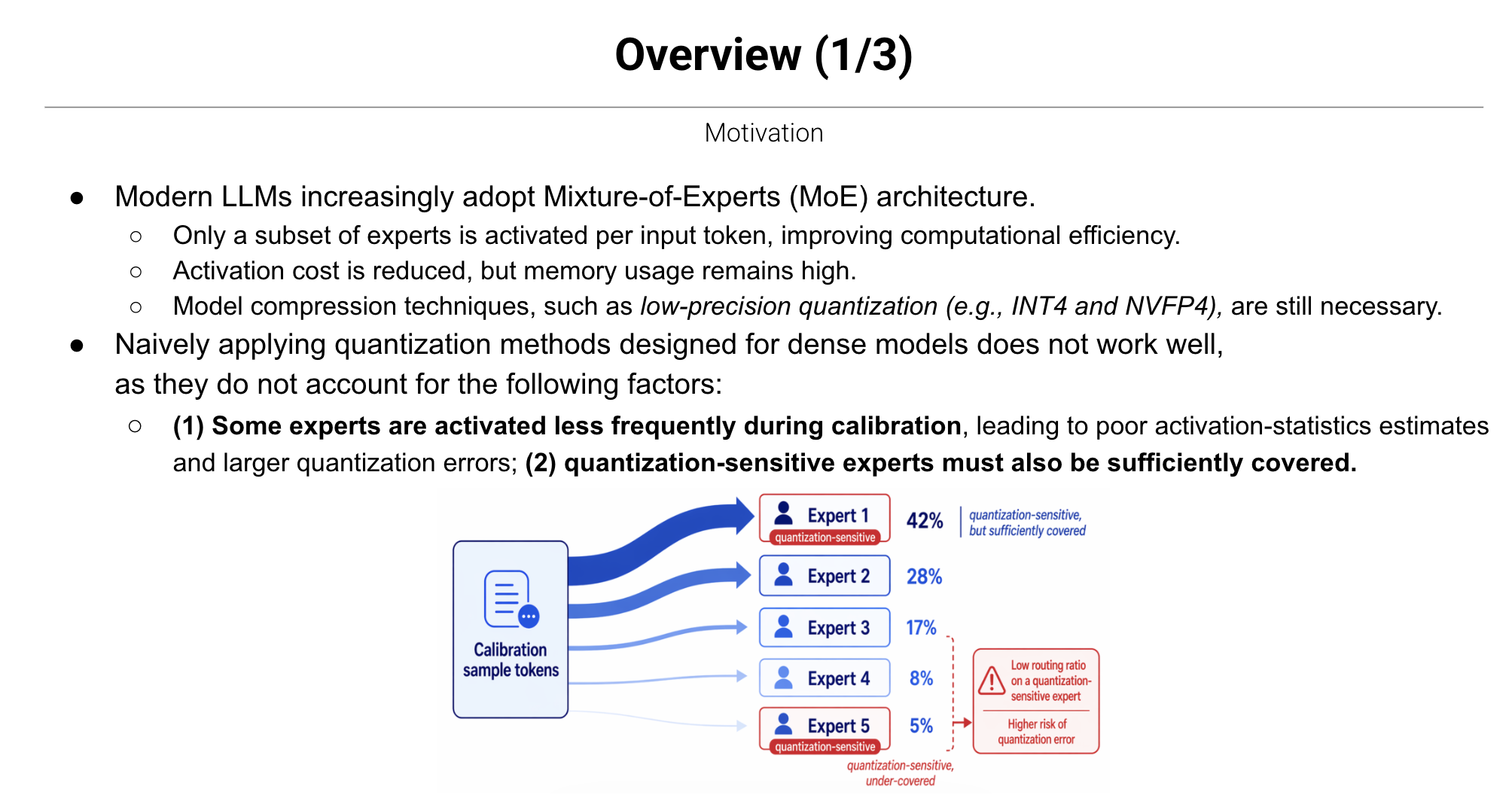
Figure 3. The Motivation slide from the PASCAL-MoE presentation
Geonho: Beyond activation frequency, there are also experts that are particularly sensitive to quantization. You can identify them from the model weights alone, without any prior calibration data, and that assessment is independent of activation frequency. Some experts are quantization-sensitive yet rarely activated. Calibration data doesn't accumulate enough for these experts, so we built a dataset that activates them more often. In short, we designed a pipeline where AI directly synthesizes samples that intentionally wake up dormant experts.
Q. Mike Tyson once said, "Everyone has a plan until they get punched in the mouth." I imagine the Nota AI team also ran into moments where the plan didn't match reality. (Laughs) Where did things go most off-track?
Geonmin: Honestly, since the proposal had laid out the big picture, there were no major issues. We had small discussions like "Should it be A or A-prime?" but we kept finding common ground quickly and finished cleanly.
Geonho: The tight schedule was tougher than reaching consensus. The first day's seminars ran until 5 p.m., so we effectively had only about 18 hours to actually work. With more cases or more data, we could have shown firmer results. We just wished we had more time for that.
(Q. How would you rate the completeness of what you produced?)
Hancheol: Not perfect, but I think we walked away with enough evidence to demonstrate practical value. We even included quantitative numbers showing how much performance improved. Hackathons usually wrap up with concept-only demos, but I think we showed a level that confirmed commercial viability.
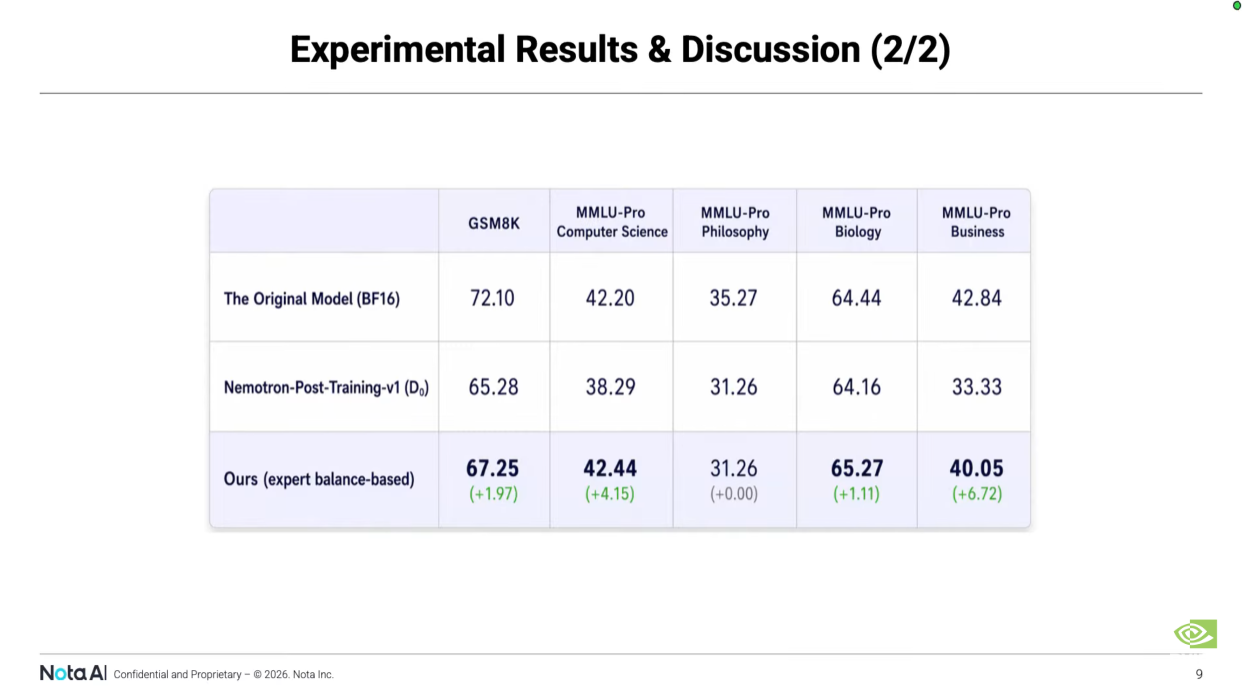
Figure 4. A slide from the PASCAL-MoE presentation showing quantitative gains over the baseline
Q. Looking at the schedule, there was a "Connect with Experts" session in the middle of the hackathon, where you could talk directly with the NVIDIA team behind Nemotron. What kinds of feedback or advice came back?
Geonho: We had two chances to talk: once during the hackathon, and once just before the presentation. The first was relatively open. We mostly used the time to ask the questions we'd had for NVIDIA itself. Since the NVIDIA team also works on MoE models, we exchanged thoughts on questions like "What do you think about MoE quantization?" and "What were the difficulties when building MoE?"
Geonmin: In the second session, we focused on the hackathon. During that conversation, the fact that we leveraged the NVIDIA software stack heavily came across naturally. As is typical with hackathons, this event was largely meant to spread the word about Nemotron. The fact that we knew Nemotron well and used it extensively came through clearly in this session, and I think it earned us some points.
Q. You moved on to the "officially optional" Overnight Sprint. We heard the three of you stayed up. What was the atmosphere like that night? Were many other teams still at it?
Geonho: The organizers basically provided seminar rooms. Some people stayed, some went home and came back. We booked a nearby accommodation and worked from there.
Hancheol: We caught short naps in between, exchanged feedback on each other's gaps, and wherever we disagreed we used Disagree & Commit to converge. It's one of Nota AI's leadership principles. That approach really helped us land on better answers.

Figure 5. The "Morning Meditation" session on Day 2's official schedule
(Q. Day 2's official schedule unexpectedly included "Morning Meditation." What were the three of you doing at that time?)
Hancheol: I'd heard NVIDIA also runs mindfulness programs at headquarters. I think this was part of that. We were polishing things up to the last minute and had no time to medi… (Laughs) we couldn't join.
Part 3. 5 Minutes: "...over there!"

Figure 6. Hancheol Park presenting the PASCAL-MoE pipeline to the judges
Q. Let's leave the rough patches behind and move on to the presentation and awards. Each team had only 5 minutes on the Final Showcase stage. That's tight. What did you choose to focus on?
Hancheol: As you said, the time was so short that we had to be selective. We put the GitHub demo on a QR code and used the full 5 minutes for the algorithm explanation. Opening with an icebreaker also worked in our favor. Our presentation slot was almost last, so the judges were pretty tired. We opened with a one-liner.
"We have compressed various LLMs so that they can run on NVIDIA edge devices, such as Jetson Nano, NX, and Orin Nano. And the next step is… over there!"
Then we pointed at the DGX Spark. The prize was a DGX Spark. We had a backup joke ready in case nobody laughed, but the judges started laughing first.
At the same time, we explicitly wove into the presentation that the outcome of this hackathon wouldn't end as research alone, but could plug straight into tools like NVIDIA NeMo Data Designer. I think that point also worked in our favor.
Q. Track C First Place and the Grand Prize were called out one after the other. So the joke landed. Did you have any sense the awards were coming too?
Geonmin: Honestly, none at all. The people who built the project know its weaknesses and limits best. We were worried about how those gaps would be exposed. But that turned out to be unfounded. Everyone was working under the same time pressure, so weaknesses and limits exist for every team, and judges focus on what teams did well. I think the judges focused on what we got right.
(Q. Did the judges explain why your team was picked when they announced the first place?)
Geonho: In the closing remarks, there was a comment that said "a team that demonstrated not only qualitative but also quantitative evaluation." These days, with tools like Claude available, other teams build very flashy demos. Many showed off something like "a PPT-generating agent" with the polish of a real product. Among all that, the fact that we presented quantitative improvement numbers alongside our work seems to have been the differentiator.
Figure 7. The demo announcement Hancheol Park posted to the hackathon Slack channel
Hancheol: On top of that, I think our pitching strategy and social media strategy played a part too. The peer review score was worth 20 points, so we shot a video of our demo and posted it to the hackathon Slack channel, then used a fun emoji combination to encourage people to leave reactions.
Q. After all that, you took home a DGX Spark with the Grand Prize. We heard there was an episode where you almost won a second one?
Hancheol: Beyond the Grand Prize gift, there was also a separate raffle giving one DGX Spark to a single participant. Geonmin came in second in that.
Geonho: Looking back, I think that was a sort of offering that brought us luck.
Geonmin: So I'm the reason we won first place. (Laughs)

Figure 8. The raffle screen where the second DGX Spark was being drawn
Part 4. Coming Back: The Path to NetsPresso®
Q. For the final stretch, let's talk about what comes after the hackathon. How does the approach you validated here connect with your day-to-day NetsPresso® work? And if it ends up reaching customers, what shape might that take?
Hancheol: There are roughly two directions.
The first is potential collaboration with NVIDIA's Model Opt team. During the hackathon, the Model Opt team reached out to us first. This team has a technique called Quantization-aware Distillation (QAD) that improves the quantization quality of Nemotron models. Since our pipeline goes deeper into the structural characteristics of MoE when generating data, they reached out to us with the expectation that applying our data to QAD might yield better performance than what they were getting with their existing data.
The second is integration into the NetsPresso® platform. Our MoE-specific quantization technique, NMQ (Nota MoE Quantization), is already being integrated into NetsPresso®'s AQ (Advanced Quantizer) module. The plan is to layer the SDG work from this hackathon on top of that. We're advancing the algorithmic and data sides together.
(Q. Tackling both algorithm and data looks like a Nota AI-specific strength. Is that a fair read?)
Hancheol: As I mentioned earlier, the algorithmic side is still mainstream. The data-centric approach is currently being explored by only a handful of research groups, so think of us as moving nimbly in that direction. We turned our attention to data when Geonho introduced us to a relevant paper. That paper was an early-stage approach itself, and we took it further with more refinement. There's still a lot to improve, but I'm convinced this is the right direction.
Q. After getting to a result like this, your teamwork must feel solid. Are there goals or projects you'd like to tackle as this team next?
Hancheol: Honestly, we already had a rough sense of each other's working styles before going in. I've been working with Geonmin for a while. So it wasn't a dramatic change, more like a confirmation that "yes, this is how it works."
Geonho: For me, I'm just glad I came in and wrapped up something that turned into a result. I hope we can take this further to bigger results, in directions like the Model Opt team collaboration and NetsPresso® platform integration we just talked about. We only showed the concept at this competition, but I personally think the direction itself is a really good one.
Q. Final question. Looking back at the whole hackathon experience, if there's something each of you would most like to say right now, please share it freely. Whether it's a reflection or a word for the readers.
Hancheol: I'm getting too old for this… just kidding. (Laughs) It was physically rough, but it was definitely meaningful work.
Geonho: This was actually my first hackathon. I learned a lot, the result came out well, and I'm satisfied.
Geonmin: It was physically tough, but it was a great opportunity to grow in such a short time.
Epilogue: What Lies Behind That Single Line
What Hancheol Park, Geonmin Kim, and Geonho Lee built over those no-sleep two days reduces to a single line: "a synthetic data generation pipeline specialized for MoE quantization." Yet behind that line lies the night they took turns sleeping between the meeting room and the accommodation, the moment they spotted a code bug while listening to a seminar and rushed to fix it, and the closing words of a 5-minute pitch that tried to capture even the future of collaboration with NVIDIA.

Figure 9. Group photo with NVIDIA Vice President Maggie Liu after the awards ceremony
※ This interview focused on the story behind the stage. The technical breakdown of "MoE quantization + synthetic data" itself will follow in a future post on the Nota AI tech blog.
If you're curious about Nota AI's model optimization technology, find us at NetsPresso®.
Stay ahead with Nota AI on LinkedIn. From edge AI trends to the latest tech updates — subscribe to Edge Insights and be the first to know. 👉 Subscribe now