NotaMoEQuantization: An MoE-Specific Quantization Method for Solar-Open-100B

Hancheol Park, Ph. D.
AI Research Engineer, Nota AI

Tairen Piao
AI Research Engineer, Nota AI

Tae-Ho Kim
CTO & Co-Founder, Nota AI

✔️ Resource : The official quantized model of Solar-Open-100B, which passed the first round of South Korea’s Sovereign AI Foundation Model project: https://huggingface.co/nota-ai/Solar-Open-100B-NotaMoEQuant-Int4
Summary
In this article, we discuss NotaMoEQuantization, Nota AI’s proprietary quantization method specialized for Mixture-of-Experts (MoE) architectures.
We demonstrate the effectiveness of NotaMoEQuantization by applying it to Upstage’s Solar-Open-100B, which passed the first round of South Korea’s Sovereign AI Foundation Model project.
We also analyze the effects of the individual techniques that make up NotaMoEQuantization, each of which was designed with the MoE architecture in mind.
Introduction
Recently released large language models (LLMs) are increasingly adopting Mixture-of-Experts (MoE) architectures over dense architectures, in which all tokens pass through a single shared feedforward network (FFN). In an MoE architecture, a router selects the top-k expert FFNs for each token, and their outputs are combined through a weighted sum to produce the final representation. A key characteristic of this sparse architecture is that, instead of activating all parameters for each token, it activates only a subset of experts. As a result, an MoE model can dramatically reduce the amount of computation required during the text generation phase compared with a dense model with the same total number of parameters.
However, although the MoE architecture reduces the number of parameters actually activated at inference time, it does not reduce the model’s total number of parameters. Therefore, in real deployment environments, there remains a clear need to apply compression techniques such as quantization in order to improve storage efficiency and reduce memory usage. The difficulty, however, is that applying quantization to an MoE architecture cannot be treated in the same straightforward manner as conventional quantization for dense architectures.
When existing quantization methods are directly applied to MoE architectures, one easily overlooked point is that preserving decoder block outputs after quantization to keep them similar to those of the original model is, by itself, not sufficient to ensure stable performance. In an MoE architecture, the router determines which experts each token is sent to by selecting the top-k experts. If quantization perturbs the router logits during this process, rerouting may occur, meaning that the set of selected experts itself can change. Notably, even if the router layer itself is not quantized, quantization of the self-attention layer alone can still affect the routing results. Such rerouting is not merely a matter of continuous-valued error; it changes the very computational path through which a token flows. Consequently, its effect on the block output can be amplified in a nonlinear manner, potentially leading to a much larger impact (Figure 1).
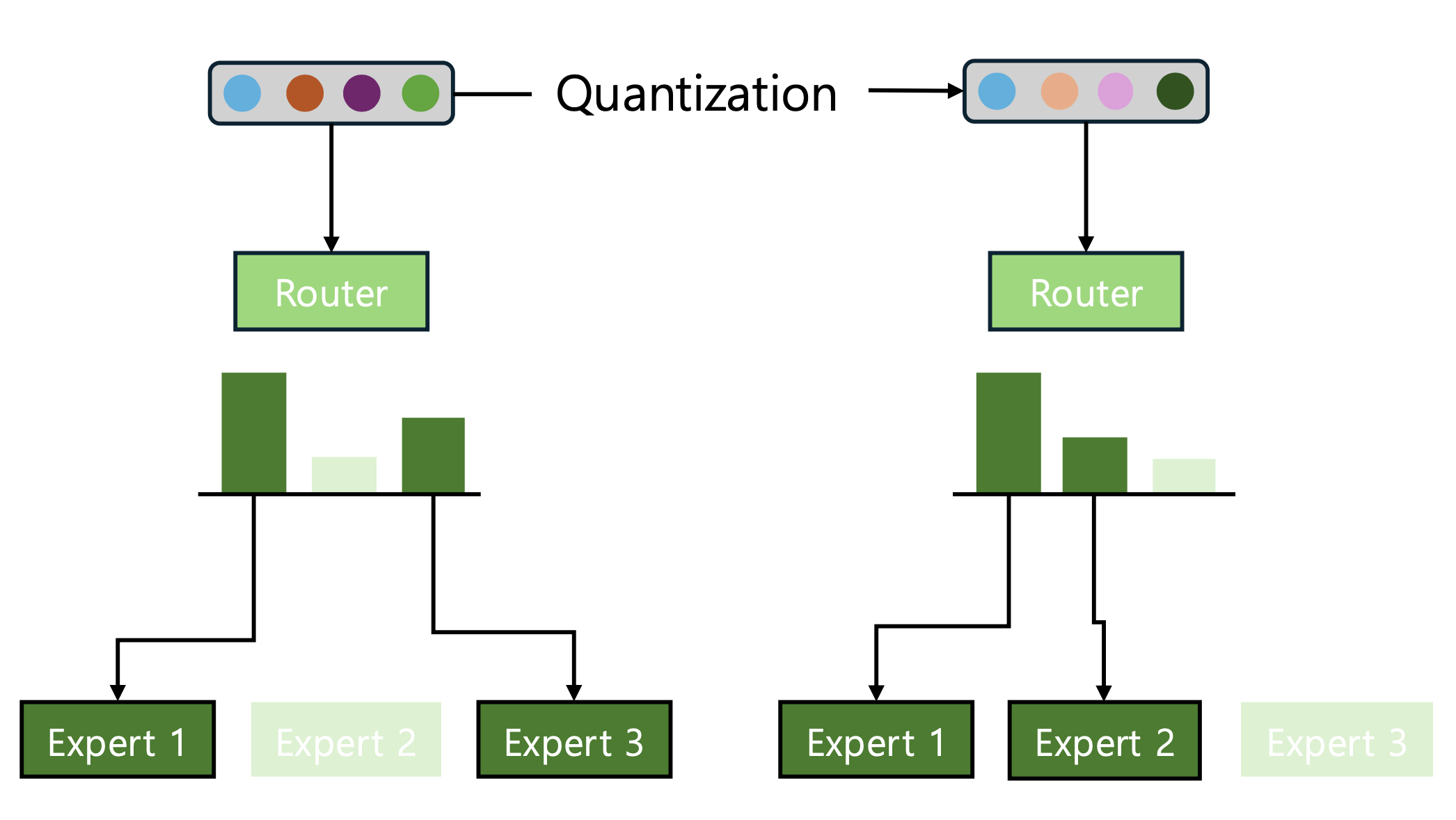
Figure 1: A diagram illustrating a case where expert selection changes due to quantization. In the example above, Expert 2 is selected instead of Expert 3, which can lead to more severe output distortion.
To mitigate this issue, a recent study by Chen et al. (2025) proposed a method that explicitly incorporates a TopK-MSE loss function when determining quantization parameters, with the goal of preserving the logits of the top-k experts as closely as possible before and after quantization. However, merely aligning the logit values of the top-k experts does not guarantee preservation of the selected top-k experts after quantization. Experts with selection probabilities close to those of the top-k experts, but excluded due to slightly lower values, may be selected instead because of quantization-induced perturbations.
In this article, we examine Nota AI’s proprietary quantization method specialized for MoE architectures, which goes beyond merely reducing the difference in top-k logit values and instead seeks to preserve the overall consistency of routing outcomes from multiple perspectives. We also evaluate the effectiveness of this method by applying it to Upstage’s Solar-Open-100B model, which passed the first round of South Korea’s Sovereign AI Foundation Model project. The quantized Solar-Open-100B model described in this article was selected as the official quantized model of Upstage’s Solar-Open-100B and has been released on Hugging Face (see Resources).
NotaMoEQuantization (NMQ)
NotaMoEQuantization (NMQ) is a quantization method proposed by Nota AI specifically for Mixture-of-Experts architectures. The core idea of NMQ is to ensure that, even after quantization, the set of top-k experts selected by the router, the corresponding probability or score distribution, and the ranking and boundary relationships among experts remain as close as possible to those of the original model. In other words, NMQ is more accurately understood not as a standalone quantization algorithm, but as a loss function used when selecting or adjusting quantization parameters or router weights. Thanks to this property, it can be applied as a plug-in to a wide range of quantization methods, including not only learning-based approaches but also optimization-based ones.
In this article, we describe the method in the form of combining NMQ with AutoRound (Cheng et al., 2024), a learning-based approach for determining quantization parameters. AutoRound uses a small set of calibration datasets to learn three quantization parameters by minimizing the mean squared error (MSE) reconstruction loss of each decoder block’s output. Specifically, it jointly tunes α and β, which adjust the range between the maximum and minimum values of each block-wise quantization group—a sub-tensor to which a single scale factor is assigned—to compute the scale factor, as well as V, which controls the rounding direction in the quantized space. In this way, each block learns quantization parameters from calibration samples so as to minimize reconstruction loss.
$$\mathcal{L}_{\text{recon}} = \|\mathbf{y}^q - \mathbf{y}^{fp}\|_2^2$$
$$y^{fp}$$ : output of the decoder block before quantization
$$\mathbf{y}_q$$ : output of the decoder block after applying the quantization parameters
In a MoE architecture, the decoder block output y is directly influenced by the router’s expert selection. Therefore, if training is performed to minimize only the reconstruction loss, the optimization may converge to an unstable solution in which each decoder output is numerically well matched, while the router’s actual expert selections are altered. To prevent this issue, we propose a router logits alignment loss function that preserves both the values and the structure of the router logits. The final loss function is constructed as follows, and in the following sections, we describe each component of the router logits alignment loss function in detail.
$$\mathcal{L} = \mathcal{L}_{\text{recon}} + \lambda \mathcal{L}_{\text{router}}$$
(1) Value alignment loss function
The first axis of the router logits alignment loss function is value alignment. This component focuses on preserving how similar the values of the top-k candidates remain before and after quantization. The notation is as follows:
$$\mathbf{z}^{fp}$$ : router logits before quantization
$$\mathbf{z}_q$$ : router logits after applying quantization parameters
(1-1) Top-k logits alignment loss function
The most intuitive form of value alignment is to directly enforce that the logit values corresponding to the top-k experts before quantization remain as close as possible after quantization. To this end, as in prior work, we use the TopK-MSE loss function.
$$\mathcal{L}_{\text{TopK-MSE}} = \|\mathbf{z}_{1:k}^q - \mathbf{z}_{1:k}^{fp}\|_2^2$$
Here, 1:k denotes the indices of the experts ranked from 1st to k-th when the full set of expert logits is sorted in descending order. The reason for aligning only the top-k logits is clear: the router’s actual decision is made within this top candidate set, so there is no strong need to closely match the logits of lower-ranked experts that are not selected. In fact, if the model is trained to reduce the discrepancy across the logits of all experts, resources may be wasted on lowering the loss for unimportant lower-ranked logits, leading to inefficient use of the gradient budget and ultimately making it harder to recover the top-k structure.
(1-2) Sigmoid-aware alignment loss function
Meanwhile, recent MoE models—including the latest families such as DeepSeek, GLM and Nemotron—use a routing scheme in which router logits are first compressed with a sigmoidand then additionally normalized into values between 0 and 1, rather than being normalized all at once with a softmax. There is a clear rationale behind this design. Because softmax normalizes the scores of multiple experts jointly, even a slight increase in the score of one expert can cause the scores of other experts to decrease relatively more quickly. As a result, during the early stages of pre-training, only a small subset of experts may be selected repeatedly, while others fail to receive sufficient learning opportunities. In contrast, sigmoid-based routing treats each expert’s score more independently, which helps reduce the concentration of scores on a few experts and allows a broader range of experts to be trained more evenly. For this reason, sigmoid-based routing can theoretically provide higher sample efficiency in training MoE models, and in practice it has also been reported to offer advantages in terms of routing stability and expert utilization. However, from a quantization perspective, the introduction of sigmoid also creates a new form of sensitivity.
When the logit value after applying the sigmoid lies near 0.5, even a small change in the logit can appear as a larger change after the sigmoid transformation. Therefore, when the post-sigmoid value falls within this sensitive region around 0.5, it is desirable to assign a larger weight so that the logits before and after quantization are more strongly aligned.
$$p^{fp} = \sigma(\mathbf{z}_{1:k}^{fp}), \quad p^q = \sigma(\mathbf{z}_{1:k}^q)$$
$$w = (p^{fp}(1 - p^{fp}))^\gamma + \varepsilon_w$$
$$\mathcal{L}_{\text{sig-aware}} = \mathbb{E} \left[ w \odot (p^q - p^{fp})^2 \right]$$
Here, the weight w is designed to increase as p, the value obtained by applying the sigmoid to the logit, approaches this sensitive region, and the additional ϵ serves as a minimum floor value for the numerical stability of the sigmoid-aware weight.
(1-3) Total value alignment loss function
The final value alignment loss is constructed by combining the two loss functions introduced above: the top-k logits alignment loss and the sigmoid-aware alignment loss. In other words, it is designed not to consider only the raw difference in values, but also to place greater emphasis on discrepancies in the regions where the router is actually more sensitive.
$$\mathcal{L}_{\text{value}} = (1 - \alpha)\mathcal{L}_{\text{TopK-MSE}} + \alpha\mathcal{L}_{\text{sig-aware}}$$
(2) Structure alignment loss function
The second axis is structure alignment. While value alignment focuses on matching the numerical similarity of the top-k logits, structure alignment is based on the observation that routing stability depends not only on the values themselves but also heavily on their relative structure. NMQ addresses this structure from two main perspectives: first, whether the ranking within the top-k experts is preserved, and second, whether the boundary margin centered on the k-th expert is maintained.
(2-1) Top-k order preservation
First, top-k rank preservation ensures that the relative ordering of the experts ranked from 1st to k-th before quantization remains unchanged after quantization. To achieve this, we introduce a rank loss function.
$$\mathcal{L}_{\text{rank}} = \mathbb{E} \left[ \text{softplus} \left( m - (z_i^q - z_{i+1}^q) \right) \right]$$
Here, m denotes the rank margin. When m=0, the loss acts simply as a constraint that enforces preservation of the ordering. The softplusfunction is a smooth and differentiable approximation of the ReLU activation function; it imposes almost no penalty when the difference between two adjacent logits, zi and zi+1, is sufficiently larger than m, but increases the loss when that difference falls short. In other words, this encourages not only the preservation of the ordering itself, but also the maintenance of a certain margin of separation.
(2-2) Boundary preservation (k vs k+1:k+n)
Next is boundary preservation. The point at which re-routing occurs most frequently is the boundary of the top-k set—that is, the cutoff region between the k-th candidate and the candidates just outside it. In particular, if the margin between the k-th and (k+1)-th candidates, or more generally between the k-th and (k+n)-th candidates, collapses, the selected set of experts can easily change. Preserving the score differences around this boundary therefore plays a very direct role in ensuring routing stability. Here, n is set as a small integer to examine candidates near the k boundary.
$$\Delta_j^{fp} = z_k^{fp} - z_{k+j}^{fp}, \quad \Delta_j^q = z_k^q - z_{k+j}^q \quad (j = 1, \dots, n)$$
$$\mathcal{L}_{\text{margin}(k:k+n)} = \|\boldsymbol{\Delta}^q - \boldsymbol{\Delta}^{fp}\|_2^2$$
$$\mathcal{L}_{\text{margin}(k:k+n)} = \frac{1}{n} \sum_{j=1}^n \|\Delta_j^q - \Delta_j^{fp}\|_2^2$$
(2-3) Total structure alignment loss function
Like the value alignment loss, the overall structure alignment loss is constructed as a weighted sum of the top-k rank preservation loss and the boundary preservation loss. Here, wrank and wmargin are weighting factors that control the relative importance of the rank preservation term and the boundary preservation term, respectively.
$$\mathcal{L}_{\text{struct}} = w_{\text{rank}}\mathcal{L}_{\text{rank}} + w_{\text{margin}}\mathcal{L}_{\text{margin}(k:k+n)}$$
(3) Router logits alignment loss function
Finally, the router logits alignment loss is defined as the sum of the value alignment loss and the structure alignment loss. In other words, the key idea of this loss function is not only to keep the logit values of the top candidates similar, but also to preserve their internal ordering and boundary relationships, so that the router’s decision-making structure remains as stable as possible even after quantization.
$$\mathcal{L}_{\text{router}} = \mathcal{L}_{\text{value}} + \mathcal{L}_{\text{struct}}$$
Experiments
To evaluate the effectiveness of NMQ, we implemented and conducted experiments using AutoRound as the baseline quantization method, as mentioned earlier. The detailed experimental setup is as follows.
Experimental Settings
We use Upstage’s Solar-Open-100B as our target MoE model. Solar-Open-100B is Upstage’s flagship open model, built on a 102B-parameter MoE architecture and trained on 1.97 trillion tokens. As a representative Korean open LLM, it also serves as a notable example within the broader movement toward South Korea’s sovereign AI foundation models. For quantization, we consider both W4A16, i.e., INT4 weight-only quantization, and NVFP4, which quantizes both weights and activations.
The quantization performance was evaluated from two main perspectives. The first was based on long-reasoning benchmarks, which require generating long sequences of tokens due to their complex reasoning processes. The second was evaluation based on general performance benchmarks, which focus on generating relatively short correct answers. For the long-reasoning benchmarks, we used MMLU-Pro and GPQA-Diamond, with the thinking budget set to 8,192 tokens. For the general performance benchmarks, we used ARC-C, ARC-E, BoolQ, HellaSwag, MMLU, PIQA, TruthfulQA, WinoGrande, and GSM-8K. Overall performance was measured as the average score across these benchmarks. In addition, we also evaluated perplexity (PPL) on WikiText-2 as an extra performance metric.
All methods used in the experiments, including AutoRound and the version combined with NMQ, were implemented using NetsPresso®, Nota AI’s model optimization platform.
Experimental Results
As shown in Tables 1 and 2, NMQ consistently outperformed the baseline across all benchmark results. In 4-bit quantization, the margin of improvement tends to be relatively small on general performance benchmarks, which mainly assess straightforward response generation, because the original performance degradation itself is already limited. In contrast, the performance gap becomes much more pronounced on long-reasoning benchmarks, which require deeper reasoning.
This difference can also be explained by the nature of the response generation process. When generating short responses, even if expert selection differs somewhat for a few tokens, the resulting impact is likely to remain limited. In long reasoning processes, however, the routing decision at each step continuously affects subsequent representation formation and next-token prediction. As a result, even a small difference in expert selection that arises early on can accumulate over the course of generation and eventually lead to a much larger divergence. From this perspective, a method that better preserves the consistency of expert selection before and after quantization is likely to show a greater relative advantage on long-reasoning benchmarks. In other words, the benefit of NMQ can be interpreted as extending beyond simply reducing token-level error, emerging more strongly through its ability to maintain routing stability throughout the entire long generation process.
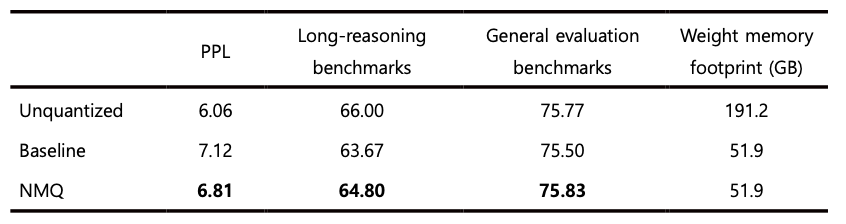
Table 1: Benchmarking results for Solar-Open-100B W4A16 quantization
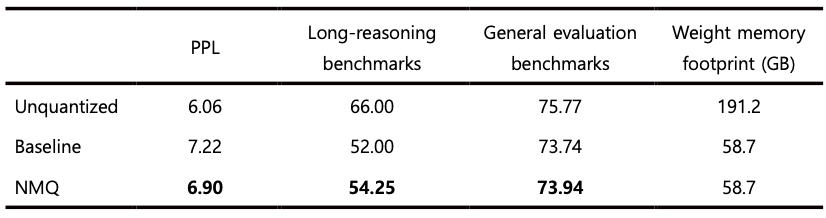
Table 2: Benchmarking results for Solar-Open-100B NVFP4 quantization
Discussion
(1) Are the individual loss terms of NMQ effective?
As shown in Table 3, in the W4A16 quantization results for Solar-Open-100B, applying only the value alignment loss function sometimes yielded slightly better performance. However, overall, there was a clear tendency for PPL to decrease as each loss term was added step by step. Since lower PPL indicates better performance, these results suggest that each of the proposed loss terms functioned effectively on the whole. In other words, the individual loss functions that make up NMQ can be interpreted as complementing quantization errors from different perspectives and making a meaningful contribution to improving overall model quality.
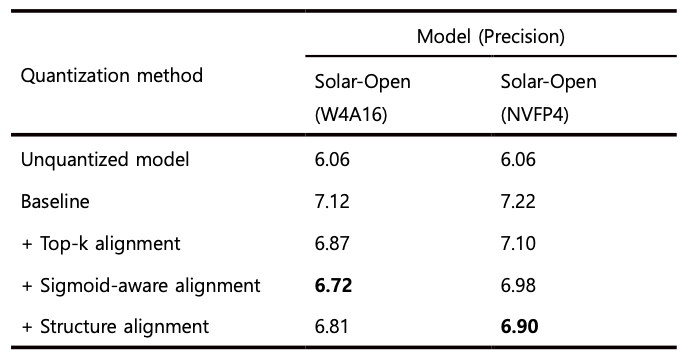
Table 3. Changes in WikiText-2 PPL when applying each loss term of NMQ
(2) How much does NMQ help preserve the experts selected before quantization?
Next, we also examined how well NMQ preserves the experts that were selected before quantization. To do this, we measured how closely the sets of experts selected for each token matched before and after quantization at each layer. The experiment used the stem, chat, math, and code subsets of Nemotron-Post-Training-Dataset-v2. A total of 616,759 tokens were passed through both the pre-quantized and post-quantized models, and the Jaccard similarity of the selected top-k experts was computed. As shown in Figure 2, applying NMQ resulted in a higher degree of agreement between the pre- and post-quantization expert sets across all layers compared with the baseline. In the largest observed case, NMQ achieved more than 11.29% higher agreement than the baseline. This shows that NMQ is effective not only in reducing output error, but also in more stably preserving the routing decisions themselves.
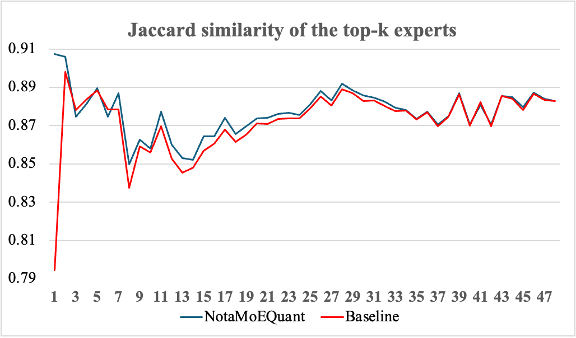
Figure 2. Agreement with the pre-quantized model in expert selection at each layer after W4A16 quantization of Solar-Open-100B
(3) Latency improvement after applying NMQ
Finally, we also evaluated the latency improvement achieved after applying NMQ. In particular, to verify the hardware acceleration effect of NVFP4, the measurements were conducted on an NVIDIA B300 environment based on the Blackwell architecture. Latency was measured using vLLM as the serving framework. The number of input and output tokens per user was set to 30,000 each, and throughput was measured under concurrency settings of 8 and 16. As shown in Table 4, all quantization methods exhibited meaningful speed improvements, and among them, NVFP4 was particularly notable in that its time to first token (TTFT) was improved by nearly 2× compared with W4A16.
These results suggest that the acceleration effect of NVFP4 may become more pronounced especially in long-input scenarios. As input length increases, the prefill stage accounts for a larger portion of the total computation, and NVFP4 likely leads to greater TTFT improvements because it provides higher efficiency for such large-scale parallel computation. In other words, the advantage of NVFP4 is not limited to a theoretical reduction in bit width, but can translate into a tangible reduction in latency in real long-context input settings.
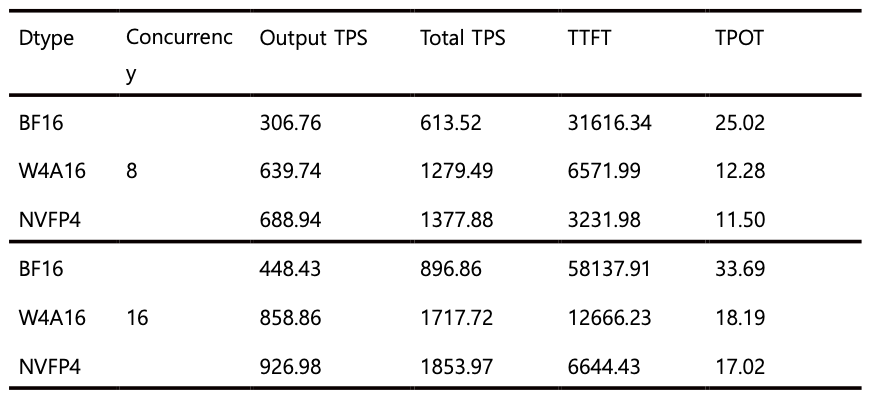
Table 4. Latency measurements of models quantized using NMQ
• TPS: Tokens per second (token throughput)
• TTFT: Mean time to first token (ms)
• TPOT: Mean time per output token (ms)
Conclusion
In this article, we examined a quantization method specialized for MoE architectures. Through the experimental results, we confirmed that NMQ can provide consistent performance improvements across a variety of settings. In particular, these findings show that, for quantization of MoE architectures, it is not sufficient to merely preserve output reconstruction well; how stably the routing behavior itself is preserved can be a key factor in maintaining performance.
Going forward, we plan to further verify the effectiveness of NMQ under even lower-precision settings. For example, under more extreme conditions such as 2-bit quantization, performance degradation is likely to become more evident even on general performance benchmarks. It will therefore be important to investigate how effectively NMQ can mitigate such degradation in those settings as well. In addition, another important direction for future work will be to confirm whether NMQ can be successfully combined not only with AutoRound, but also with other quantization methods.
We also plan to release the NMQ implementation used in our experiments through NetsPresso® in the near future. Through this release, we hope that more researchers and developers will be able to directly apply and validate NMQ in real-world MoE quantization settings.
References
[1] Chen et al. EAC-MoE: Expert-Selection Aware Compressor for Mixture-of-Experts Large Language Models. In Proceedings of ACL 2025.
[2] Cheng et al. Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs. In Proceedings of EMNLP 2024 Findings.
📧 이 연구에 대해 추가로 궁금한 사항이 있으시면 아래 이메일 주소로 언제든지 문의해 주세요: contact@nota.ai.