ERGO: Efficient High-Resolution Visual Understanding for Vision-Language Models

Jewon Lee | Wooksu Shin | Seungmin Yang | Ki-Ung Song | Donguk Lim | Jaeyeon Kim | Tae-Ho Kim | Bo-Kyeong Kim
EdgeFM Team, Nota AI
✔️ Resources for more information: GitHub, ArXiv, Project Page, Demo.
✔️ Accepted at ICLR 2026.
Summary
Efficient coarse-to-fine pipeline: A two-stage reasoning pipeline that first processes low-resolution inputs to identify task-relevant regions and then re-encodes them at higher resolution, reducing computational cost while preserving essential information.
Reward for reasoning-driven perception: With our proposed reward, the policy model learns that relying solely on accurate object localization is not always optimal and that contextual knowledge can often be more beneficial.
State-of-the-art performance with fewer vision tokens: ERGO surpasses competitive methods in accuracy on multiple high-resolution benchmarks, while reducing vision token counts and delivering practical speedups.

Introduction
In the rapidly evolving field of Large Vision-Language Models (LVLMs), the ability to process high-resolution images is becoming increasingly important for real-world applications. However, increasing image resolution inevitably causes a surge in the number of visual tokens, resulting in substantial computational overhead and latency. While "thinking with images" models have begun to reason within the visual domain, they typically operate in a perception-driven paradigm: they must clearly perceive an object at high resolution to reason about it. This makes them inefficient or ineffective when presented with low-resolution "coarse" views where fine details are lost.
Key Messages of the Paper
At its core, ERGO is built on a simple idea: the model learns to reason about where meaningful information is likely to be. By leveraging contextual cues from the scene together with the text query, it can infer task-relevant regions even when the target object is small or ambiguous. Through reinforcement learning, ERGO encourages the model to use surrounding context to guide visual exploration, leading to more efficient and reliable visual reasoning.
Significance/Importance of the Paper
ERGO represents a significant shift toward efficient high-resolution understanding. It is the first to demonstrate that aligning visual exploration with efficiency objectives through reinforcement learning (RL) can actually improve task-solving ability. Its practical importance is highlighted by its compatibility with production-grade engines like vLLM, where it provides real-world latency reductions (up to 3x) that theoretical pruning methods often fail to deliver.
Summary of Methodology
ERGO’s training objective is explicitly aligned with vision-processing efficiency in a reinforcement learning (RL) framework. Given an image and a text query, the pipeline operates in two stages: (1) the policy model predicts bounding-box coordinates for the task-relevant region with a thinking trace, and (2) the cropped region at original resolution is fed back for final answer generation.
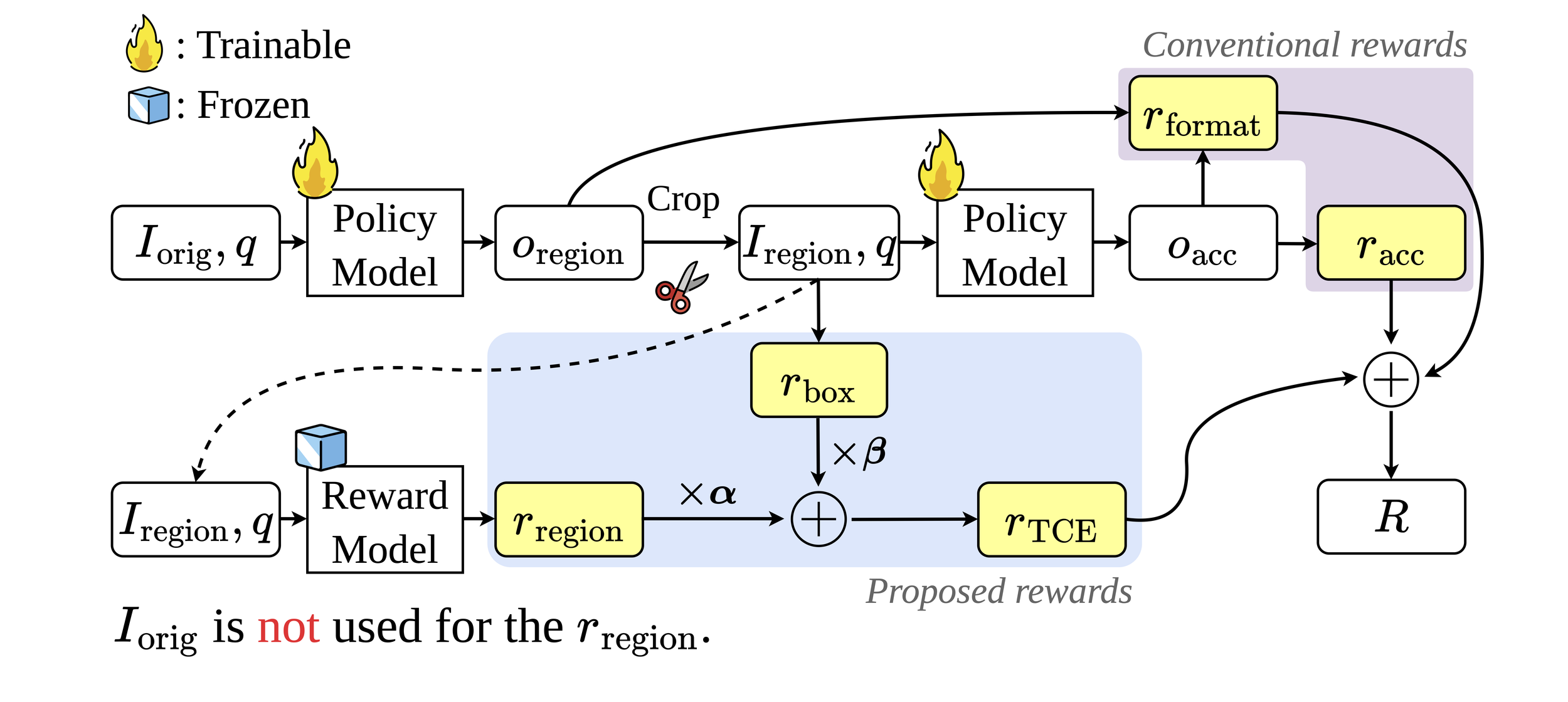
Reward Design
1. Region-Verification Reward
Task performance is evaluated using only the cropped region and the query, without access to the original image. This encourages the policy model to identify informative, self-contained regions that preserve sufficient information for accurate reasoning.
2. Box Adjustment Reward
A complementary reward that regularizes the size of the selected region. It penalizes overly large crops based on the area ratio, preventing the trivial strategy of selecting the entire image while allowing flexible region selection.
3. Task-Driven Contextual Exploration (TCE) Reward
The main reward combining region-verification and box adjustment:
This enables the policy model to learn robust and efficient region selection strategies for vision-grounded reasoning.
4. Final Reward Formulation
The overall reward is a linear combination of three components:
, where the accuracy reward bridges the training-test mismatch and the format reward enforces well-structured outputs.
Experimental Results
We evaluated ERGO across several high-resolution benchmarks to measure its accuracy and efficiency compared to state-of-the-art models and other RL-based optimization methods.
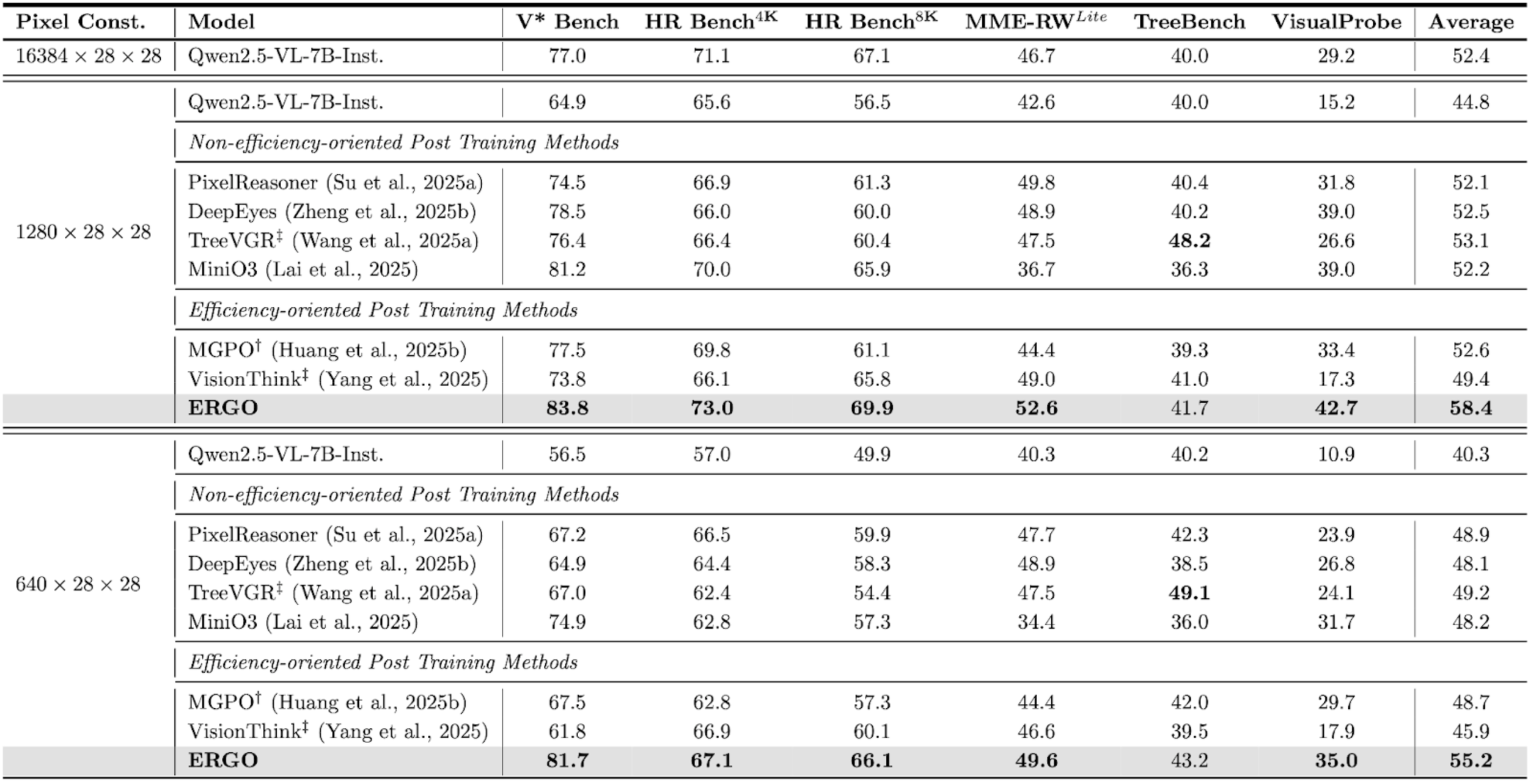
Benchmark Performance:
Under controlled input-resolution (pixel) constraints, ERGO demonstrates a clear performance advantage over both the original model and existing post-training methods. When models are evaluated with comparable visual input budgets, ERGO consistently achieves higher benchmark scores, indicating that its gains come not from processing more visual information, but from using visual computation more effectively. Here, † indicates results reproduced using the authors’ code with our evaluation setup, while ‡ denotes results obtained using each method’s original inference pipeline.
Efficiency Analysis
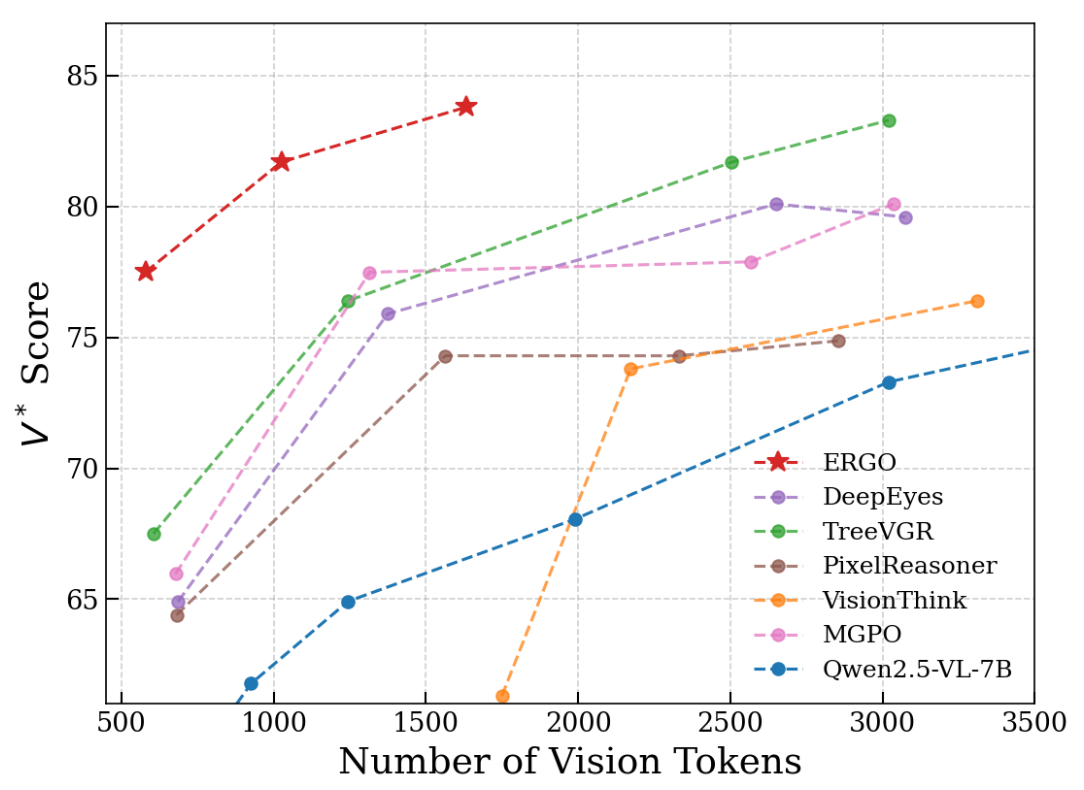
ERGO significantly improves the efficiency–performance trade-off in high-resolution visual reasoning. As shown in Figure 1, existing approaches typically achieve higher accuracy by increasing the number of vision tokens, leading to higher computational cost. In contrast, ERGO consistently achieves stronger reasoning performance while using substantially fewer visual tokens, demonstrating that reasoning-guided perception enables more effective allocation of visual computation. Rather than processing the entire image densely, ERGO selectively refines task-relevant regions, shifting the efficiency frontier toward higher accuracy at lower token budgets.
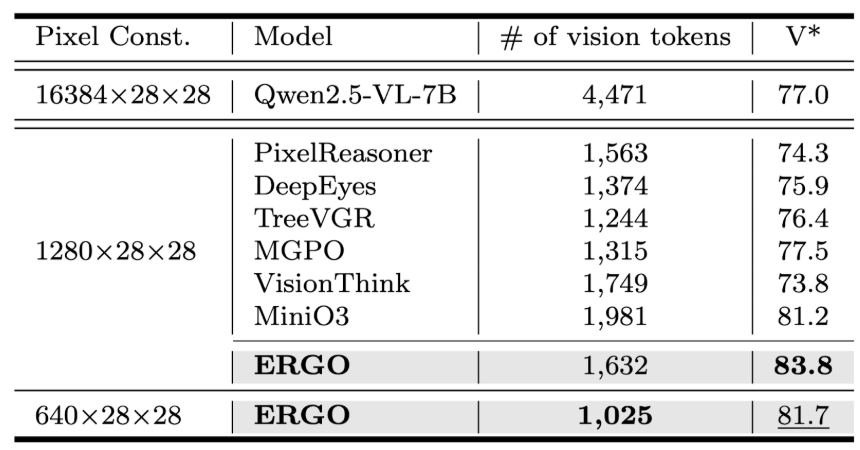

The efficiency advantage is further confirmed in Tables 1 and 2. Under comparable pixel constraints, ERGO achieves higher V* scores while requiring significantly fewer vision tokens and lower inference latency. Notably, ERGO reaches a V* score of 83.8 with only 1,632 tokens and maintains strong performance (81.7) with just 1,025 tokens, while also achieving the fastest runtime among compared methods. These results show that ERGO improves not only token efficiency but also practical deployment efficiency, enabling better reasoning performance with reduced computational cost and latency.
Ablation studies
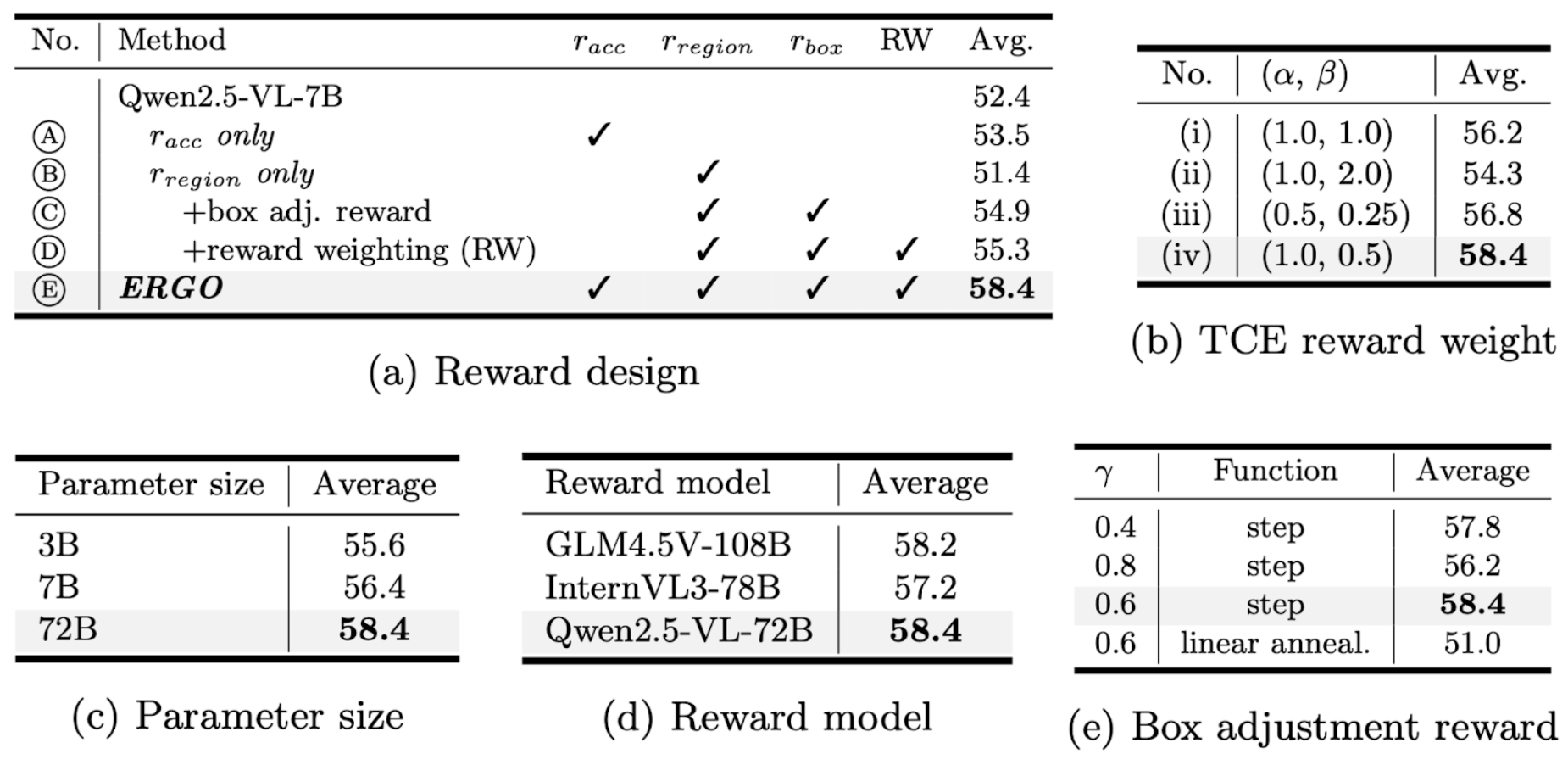
We conduct ablation studies to understand which components drive ERGO’s efficiency gains. Results show that performance improves consistently as each reward component is added, indicating that accurate reasoning alone is insufficient without learning effective region selection. In particular, region and box-adjustment rewards play a key role in guiding the model toward task-relevant areas while avoiding unnecessary visual computation. Additional experiments on reward weighting, parameter scale, and reward models further confirm that ERGO’s improvements come from a balanced reward design rather than a single architectural change.
Conclusion
The ERGO framework marks a significant advancement in the efficiency of high-resolution visual understanding for LVLMs. By shifting the paradigm from perception-driven to reasoning-driven perception, we have demonstrated that models can effectively use contextual cues to overcome the limitations of image downsampling. Our results on benchmarks prove that ERGO not only reduces computational overhead by up to 3x but also achieves superior accuracy by focusing limited visual tokens on the most task-relevant information. This approach provides a scalable, deployment-ready solution for complex vision-language tasks where both high-resolution detail and inference speed are critical.
📧 이 연구에 대해 추가로 궁금한 사항이 있으시면 아래 이메일 주소로 언제든지 문의해 주세요: contact@nota.ai.