Efficient LLaMA-3.2-Vision by Trimming Cross-attended Visual Features

Jewon Lee | Ki-Ung Song | Seungmin Yang | Donguk Lim | Jaeyeon Kim | Wooksu Shin | Bo-Kyeong Kim | Tae-Ho Kim
EdgeFM Team, Nota AI

Yong Jae Lee, Ph. D.
Associate Professor, UW-Madison
Summary
Our method, Trimmed-Llama, reduces the key-value cache (KV cache) and latency of cross-attention-based Large Vision Language Models (LVLMs) without sacrificing performance.
We identify sparsity in LVLM cross-attention maps, showing a consistent layer-wise pattern where most visual features are selected in early layers, with little variation in later layers.
Our work has been accepted to the CVPR 2025 ELVM (Efficient Large Vision Language Model) Workshop.
Key Messages of the Paper
Visual token reduction lowers inference costs in large vision-language models (LVLMs) by pruning redundant image features. Unlike prior work focused on self-attention-only LVLMs, we target cross-attention-based models, which deliver superior performance. We observe that the key-value (KV) cache for image tokens in cross-attention layers is significantly larger than that for text tokens in self-attention layers, creating a major compute bottleneck.
To address this, our method, Trimmed Llama, leverages sparsity in cross-attention maps to prune unnecessary visual features without additional training. By reducing visual features by 50%, Trimmed Llama cuts KV cache demands, lowers inference latency, and reduces memory usage—all while maintaining benchmark performance.
Significance/Importance of the Paper
We observe that the KV cache for image tokens in cross-attention layers is much larger than for text tokens in self-attention layers, creating a compute bottleneck. To address this, we selectively prune redundant visual features using cross-attention sparsity.
Summary of Methodology

Image features are pruned in the first cross-attention block using a criterion derived from attention weights.
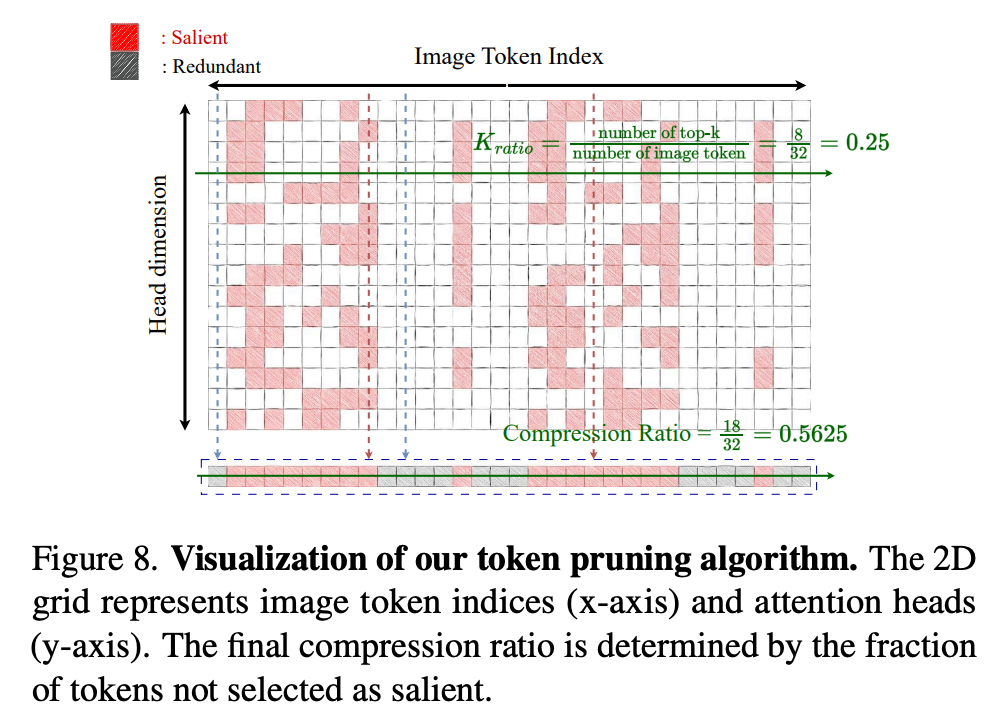
Our method uses headwise attention scores from language sequences to remove unimportant image features. In the first cross-attention layer, each head selects the top-k most salient features based on attention scores. The union of these top-k sets across all heads forms the final selection, providing a focused image representation.
Experimental Results
As described below, we achieved third place out of 25 teams in Subtask B (binary multilingual MGT detection) of Shared Task 1, with an F1 Macro Score of 0.7532.

Our method consistently outperforms or achieves comparable performance while leveraging 40∼50% of the image features. Notably, the pruning ratios are adaptively allocated for each task, as evidenced by LLaVA-Bench, an open-ended generation task utilizing more image features compared to other benchmarks.

Our method reduces latency by pruning key and value inputs in the cross-attention layers. Since image features are pruned after the first cross-attention layer, both the key-value projections and the attention operations are consequently reduced. Furthermore, the impact of the reduction grows more significant with larger batch sizes.
Conclusion
Cross-attention-based models, like LLaMA-3.2-Vision, achieve outstanding performance and efficiency using high-quality, proprietary datasets. We expect future open-source models with similar architectures to drive further advancements.
If you have any further inquiries about this research, please feel free to reach out to us at following 📧 email address: contact@nota.ai.
Furthermore, if you have an interest in AI optimization technologies, you can visit our website at 🔗 netspresso.ai.