The Real Reason TurboQuant Shook the Market: AI Optimization Has Gone Mainstream

Jaehoon Lee
Technical Content Manager, Nota AI
In March, a single official announcement from Google Research rocked trillions of won in the market capitalization of U.S. infrastructure and semiconductor stocks. The catalyst: TurboQuant, a study showing that the KV cache, a key bottleneck in large language models (LLMs), could be compressed to just 3.5 bits per element, cutting memory usage by a factor of six. "If AI models can use this little memory, won't demand for HBM collapse?" That fear swept through the market.
But the picture changes when you look more closely. The cost of processing long contexts, a requirement for enterprise AI and multi-agent environments, remains far too high for widespread adoption. In other words, a sixfold reduction in cost does not signal shrinking demand. Instead, it can be read as a trigger that unlocks the massive pool of enterprise demand that has been suppressed by prohibitive costs.
Interpretations and forecasts continue to diverge, but what deserves our attention is the fact itself: a single, still-unvalidated research-stage algorithm triggered this level of market sensitivity. Dismissing this as a mere technical episode would understate the reaction, which was both immediate and enormous.
Let us examine the three decisive signals behind why a single algorithm moved trillions of won.
1. The Macro Signal: A 1,000× Mandate and the Rise of 'Intelligence per Joule'
First, the backdrop. The entire AI industry is hitting an efficiency wall.
In March of this year, researchers from over 30 institutions, including AI luminary Yann LeCun and teams from Google, NVIDIA, OpenAI, Stanford, AMD, and SK Hynix, jointly published "AI+HW 2035: Shaping the Next Decade." These are competitors. They came together for one reason: the urgency of setting a direction now for the next decade of AI and hardware.
The report's core message is unambiguous:
"AI training and inference efficiency must improve by a factor of 1,000 over the next decade."
For years, the industry's sole doctrine has been "Bigger is Better": larger models, more parameters, longer contexts. But the numbers in the report are sobering. Training a single frontier model consumes millions of kilowatt-hours of energy, and AI data center power demand is approaching nation-scale levels. On the current trajectory, the training cost of a single frontier model will rival the annual electricity consumption of a small country before this decade is out.
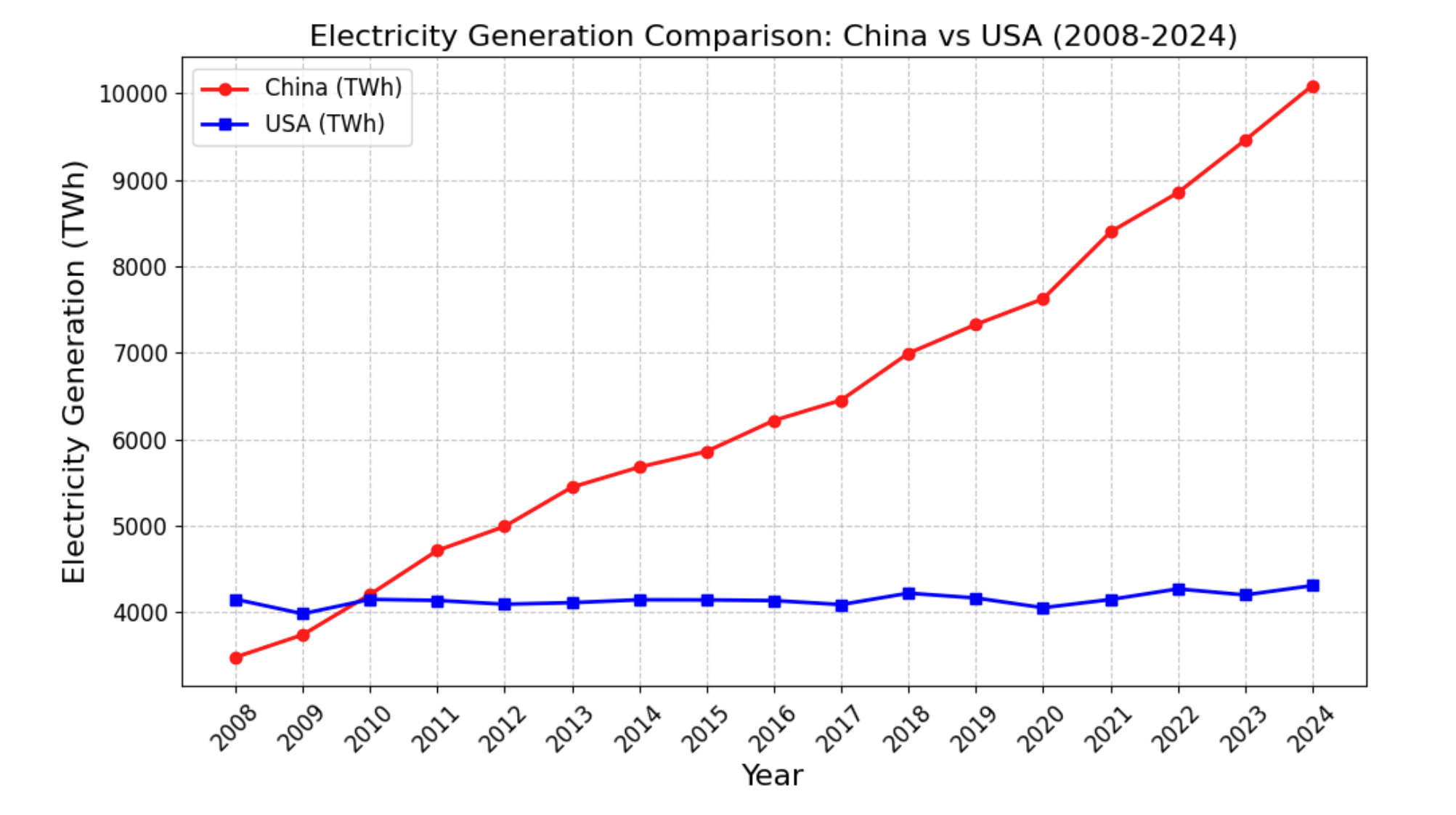
Figure 1: Electricity generation in China vs. the U.S. (2008–2024). China's output has roughly tripled while the U.S. has plateaued, underscoring the need for energy-efficiency gains in the AI era. (Source: AI+HW 2035)
The report identifies the root cause as the Memory Wall. In today's AI systems, the energy cost of moving data already exceeds the energy cost of computation itself. No matter how fast a chip can compute, if the data-fetch bottleneck remains, overall system efficiency stalls. The solution cannot come from hardware alone; algorithms must reduce the sheer volume of data that needs to move in the first place.
The report therefore defines an unprecedented level of efficiency improvement as the top priority for the coming decade. According to the report, this target cannot be reached through incremental gains at any single layer; it requires innovations across hardware, algorithms, and system architecture to compound multiplicatively. The very metric of success is also changing. The benchmark is no longer raw FLOPs, but "Intelligence per Joule," the amount of meaningful output produced per joule of energy.
Fittingly, the first key directions listed in the report's algorithm layer align precisely with this vision: quantization, pruning, and advanced model compression.
2. The Hardware Signal: NVIDIA's 'Token Factory Economics'
This macro-level diagnosis is already materializing in hardware.
At NVIDIA GTC 2026, which wrapped up last month, CEO Jensen Huang likened the data center to a "Token Factory" and introduced a new economic formula:
Revenue = Tokens per Watt × Available Gigawatts
The implication is clear. A data center's power budget is fixed. A 1-gigawatt facility cannot become a 2-gigawatt facility. That leaves a single variable to determine revenue: tokens produced per watt, i.e., how much inference can be squeezed out of every unit of power. Simply stockpiling GPUs no longer pencils out; the era of scaling by adding infrastructure has given way to one of relentless optimization and specialization, a reality the industry's rule-maker has validated with its own bets.
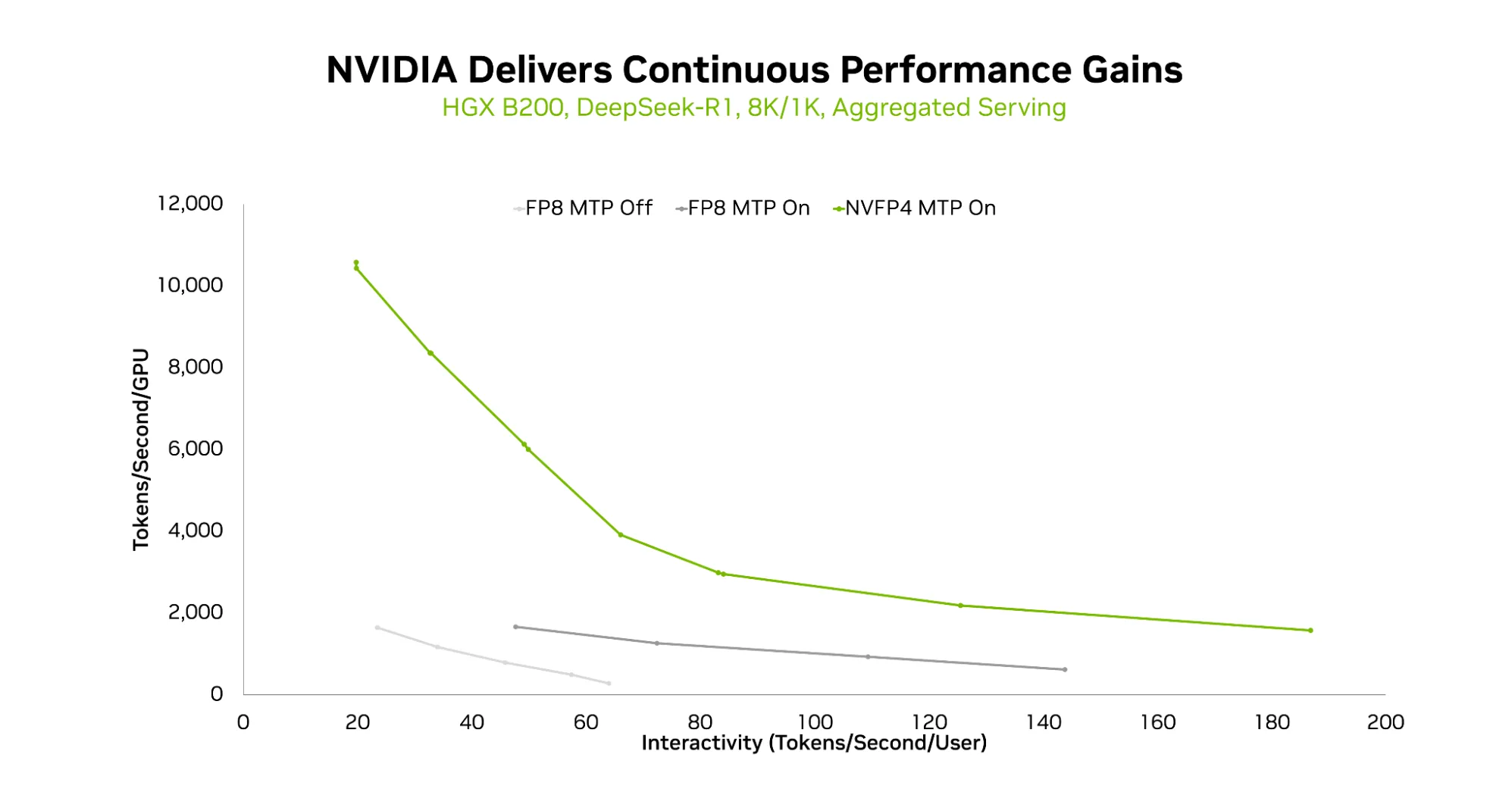
Figure 2: Throughput comparison by precision when serving DeepSeek-R1 on NVIDIA HGX B200. The NVFP4 (4-bit) + MTP configuration achieves approximately 2× the throughput of FP8. (Source: NVIDIA Technical Blog)
NVIDIA did not stop at words. The fifth-generation Tensor Cores in the Blackwell architecture feature native NVFP4, 4-bit floating-point arithmetic built directly into the silicon. The payoff: roughly 2× compute throughput over FP8 alongside 1.8× memory savings. Even when a large model like DeepSeek-R1 is quantized to FP4, accuracy loss stays within 1%. Native support has already landed in major serving frameworks including TensorRT-LLM and vLLM.
NVIDIA went further still. Late last year, it acquired inference-chip startup Groq for \$20 billion and announced plans to integrate the technology into its next-generation Vera Rubin platform. Purchase-order projections from Blackwell through Vera Rubin total \$1 trillion through 2027.
The conventional assumption is that hardware passively absorbs whatever computational load advances in algorithms impose. But today, hardware is leading the charge by putting 4-bit native arithmetic front and center, essentially laying down the rules and telling the market: "Optimize to this spec." When the rule-maker bets this decisively, low-bit quantization is no longer a lab curiosity.
3. The Algorithm Signal: TurboQuant, the Technology Behind the Tremor
The industry set the direction. Hardware laid the groundwork. And precisely into that opening, TurboQuant arrived, aimed at exactly the same target. It is time to look inside the technology that shook the market.
Published by Google Research, TurboQuant compresses the KV cache to just 3.5 bits per element, reducing memory usage by roughly 6× while preserving performance on par with the 16-bit original. Its most compelling feature is that it requires no calibration dataset or fine-tuning; it is data-oblivious, meaning it can be applied immediately out of the box.
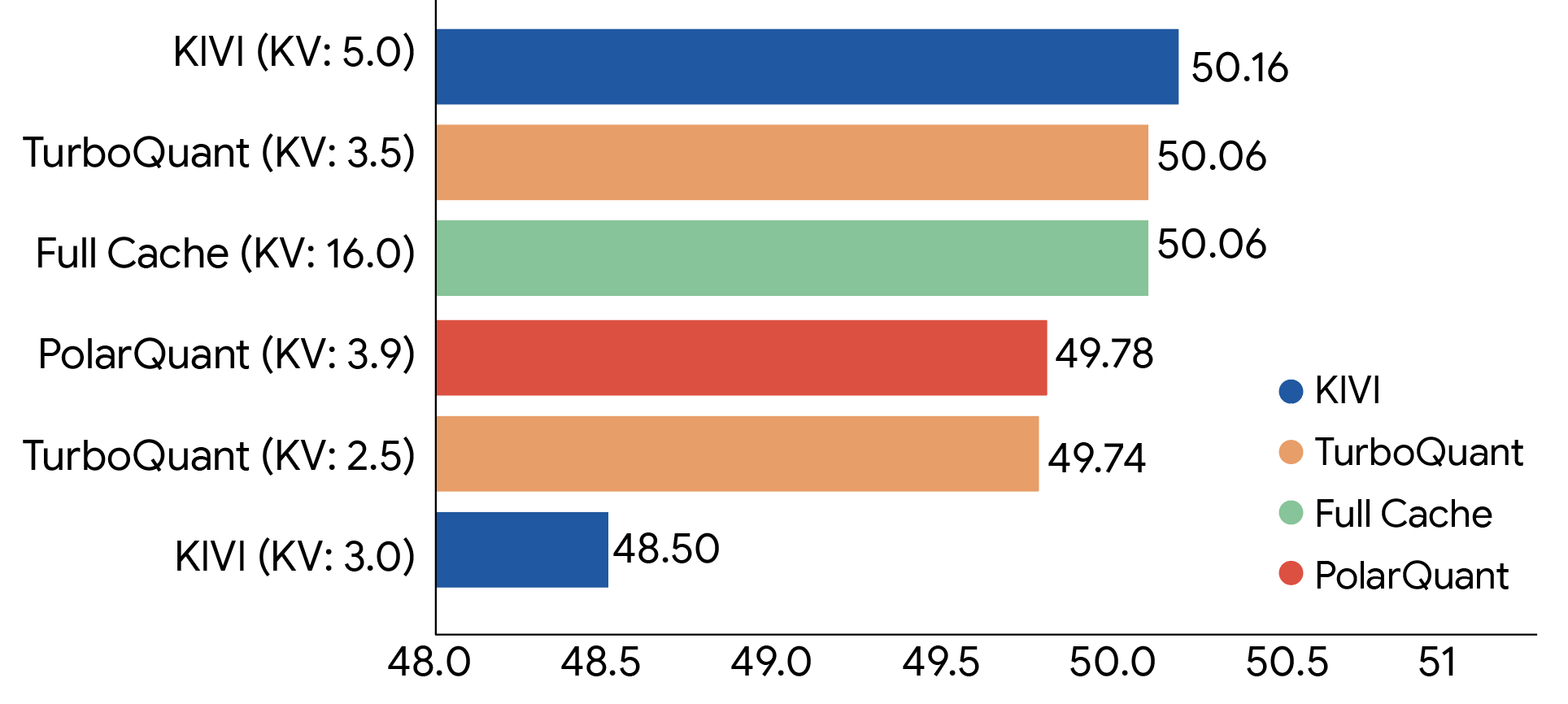
Figure 3: LongBench accuracy comparison across KV cache quantization methods. TurboQuant maintains the same score (50.06) as the 16-bit Full Cache even at 3.5-bit compression. (Source: Google Research)
Technically, TurboQuant is a two-stage pipeline. The first stage, PolarQuant, eliminates normalization overhead through polar-coordinate transformation. The second, QJL, compresses the residual to 1 bit while preserving attention accuracy. Crucially, the method comes with a mathematical guarantee: its compression loss stays within a constant factor (approximately 2.7×) of the theoretical lower bound.
Production-level validation, such as integration into serving frameworks, still lies ahead. Yet what makes this work stand out is its timing. As the industry enters the era of agentic AI, the volume of intermediate-state data that models must handle during inference is growing exponentially. This is the real signal the research sends to the algorithm ecosystem.
Until now, model compression has been a trade-off, a concession that sacrificed some degree of performance. TurboQuant has demonstrated that extreme compression of large models without degrading intelligence is mathematically achievable. Compression technology has been elevated from a mere cost-reduction tool to a mission-critical capability that will determine the viability of future AI services, and this research declares that fact from the front lines.
Where All Three Signals Point
Let us place the three signals side by side.
Over 30 institutions declared that the defining challenge of the next decade is a 1,000× efficiency gain, with quantization, pruning, and model compression as the key levers. NVIDIA redesigned its hardware around 4-bit native arithmetic and positioned "tokens per watt" as the new unit of the AI economy. Google's TurboQuant, still a research-stage effort with no framework integration, moved trillions of won in semiconductor market capitalization the moment it was unveiled.
Vision, hardware, algorithm. All three layers point to the same place.
This is not a niche interest of a few researchers. It is structural evidence that the center of gravity of the AI industry is shifting.
Until now, the AI race has been a game of "who can secure the most GPUs." That premise still holds. But under the fixed ceiling of a 1-gigawatt power budget, the calculus changes. Going forward, the contest will be decided by the ability to push model density and energy efficiency to the limit on top of the infrastructure already in hand.
References
[1] AI+HW 2035: Shaping the Next Decade — Deming Chen, Jason Cong, et al. (2026)
[2] TurboQuant: Redefining AI Efficiency with Extreme Compression — Google Research Blog (2026.3)
[3] Introducing NVFP4 for Efficient and Accurate Low-Precision Inference — NVIDIA Technical Blog
[4] GTC 2026 Keynote by Jensen Huang — NVIDIA GTC San Jose (2026.3)
[5] Memory stocks fall after Google posts AI development TurboQuant — CNBC (2026.3.26)
If you have any further inquiries about this research, please feel free to reach out to us at following email address: 📧 contact@nota.ai.
Stay ahead with Nota AI on LinkedIn. From edge AI trends to the latest tech updates — subscribe to Edge Insights and be the first to know. 👉 Subscribe nowFurthermore, if you have an interest in AI optimization technologies, you can visit our website at 🔗 netspresso.ai.