Shortened LLM: A Simple Depth Pruning for Large Language Models

Bo-Kyeong Kim
Senior Researcher, Nota AI
Introduction
Large Language Models (LLMs) are revolutionizing the world. According to the scaling laws [Kaplan et al, 2020] and additional evidence, bigger model sizes yield better-performing models. However, their financial and computational demands are significant. This study aims to reduce the inference costs of LLMs through structured pruning, which is effective in achieving hardware-independent speedups.
🍀 Resources for more information: GitHub, ArXiv.
🍀 Accepted at ICLR’24 Workshop on ME-FoMo and featured on Daily Papers by AK.
Overview
An LLM is a stack of multiple Transformer blocks [Vaswani et al., 2017], each of which contains a multi-head attention (MHA) module and a feedforward network module (FFN). In terms of structured pruning over LLMs, width pruning has initially been attempted. LLM-Pruner [Ma et al., 2023] and FLAP [An et al., 2024] reduce the network width by pruning attention heads of MHA modules and intermediate neurons of FFN modules. In this work, we propose a depth pruning method for LLMs by removing some Transformer blocks. We perform a comparative analysis between two pruning dimensions, network width vs. depth, regarding their impact on the inference efficiency of LLMs, as shown in Figure 1.

Figure 1. (a) Comparison of pruning units. Width pruning reduces the size of projection weight matrices. Depth pruning removes Transformer blocks, or individual MHA and FFN modules. (b) Efficiency of pruned LLaMA-7B models on an NVIDIA H100 GPU. Compared to width pruning by FLAP and LLM-Pruner, our depth pruning achieves faster inference with competitive PPL on WikiText-2 (left) and offers a better latency-throughput trade-off (right; M: batch size).
Method
Figure 2 shows our approach. We begin by calculating the importance of each block to identify which blocks should be removed. Then, we perform one-shot pruning by removing several blocks simultaneously. Once the pruned network is obtained, we apply LoRA retraining [Hu et al., 2022] to recover the generation performance in a fast and memory-efficient manner.
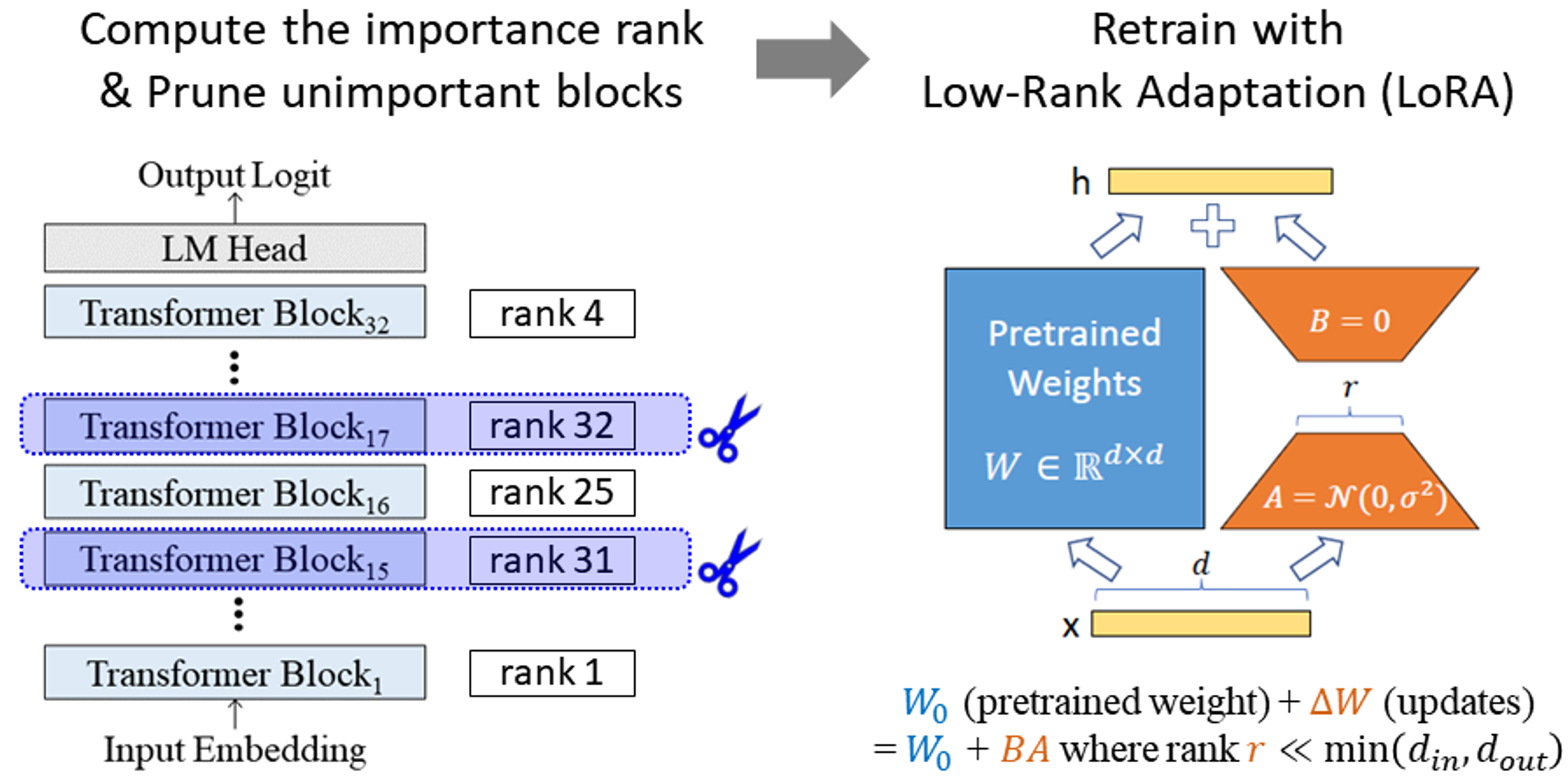
Figure 2. Our depth pruning approach. After identifying unimportant blocks with straightforward metrics, we perform one-shot pruning followed by light retraining. Right LoRA figure was sourced from Hu et al. [2022].
We consider the following pruning criteria to evaluate the significance of each block. Specifically, the linear weight matrix is denoted as $\mathbf{W}^{k,n} = \left[W_{i,j}^{k,n}\right]$ with a size of $(d_{\text{out}}, d_{\text{in}})$, where $k$ represents the operation type (e.g., a query projection in MHA or an up projection in FFN) in the $n$-th Transformer block. The weight importance scores are calculated at the output neuron level, followed by summing these scores to assess the block-level importance.
Taylor+ criterion. For a given calibration dataset $D$, this criterion is derived from the change in the training loss $\mathcal{L}$ when a weight is pruned and replaced with a zero value [LeCun et al.,1989; Molchanov et al., 2019]: $\left| \mathcal{L}(W_{i,j}^{k,n}; D) - \mathcal{L}(W_{i,j}^{k,n} = 0; D) \right| \approx \left| \frac{\partial \mathcal{L}(D)}{\partial W_{i,j}^{k,n}} W_{i,j}^{k,n} \right| $, where researchers have shown that it’s sufficient to use only the first-order term. We define the block score as $I_{\text{Taylor}}^n = \sum_k \sum_i \sum_j \left| \frac{\partial \mathcal{L}(D)}{\partial W_{i,j}^{k,n}} W_{i,j}^{k,n} \right|$. The symbol `+' denotes a heuristic that keeps the initial and final few blocks unpruned.
Perplexity (PPL) criterion. We physically remove each transformer block and monitor its impact on PPL using the calibration set $D$: $I_{\mathrm{PPL}}^n = \exp \left\{ -\frac{1}{SL} \sum_{s} \sum_{l} \log p_{\theta^{n}}(x_{l}^{(s)} | x_{<l}^{(s)}) \right\}$, where $\theta^{n}$ denotes the model without its $n$-th block, and $s = 1, \ldots, S$ and $l = 1, \ldots, L$ are the indices for sequences and tokens in $D$. As shown in Figure 3, several blocks are identified as removable, showing only a slight effect on the PPL metric. The elimination of initial and final blocks significantly degrades the performance, which necessitates keeping them unpruned.

Figure 3. Estimated importance of each Transformer block on the calibration set. Blocks with lower PPL scores are pruned.
Results
Our focus is on accelerating LLM inference under small-batch conditions caused by hardware restrictions. Such situations are relevant for deploying LLMs on memory-limited local devices. Figure 4 shows quantitative results, and Figure 5 presents qualitative generation examples.
Reducing weight sizes via width pruning is ineffective in speeding up generation, because of the memory-bound nature of LLM inference. Additionally, width pruning can even degrade the speed when the resulting weight sizes are unsuitable for GPU capabilities.
Our method achieves inference speedups while obtaining similar zero-shot performance compared to width pruning methods. We demonstrate that notable speed gains can only be achieved using depth pruning, which entirely removes some modules.

Figure 4. Results of pruned LLaMA-1-7B [Touvron et al., 2023] and Vicuna-v1.3-13B [Chiang et al., 2023]. The width pruning methods of Wanda-sp [Sun et al., 2024; An et al., 2024], FLAP [An et al., 2024], and LLM-Pruner [Ma et al., 2023] often degrade inference efficiency. In contrast, our depth pruning approach enhances generation speed and competes well in zero-shot task performance.

Figure 5. Generation examples. Given an input prompt about 'AI can create a logo in seconds,' the pruned models generate outputs that are similar to those of the original models.
Conclusion
We compress LLMs through the one-shot removal of several Transformer blocks. Despite its simplicity, our depth pruning method (i) matches the zero-shot performance of recent width pruning methods and (ii) improves inference speeds in small-batch scenarios for running LLMs.