[NetsPresso® x AI Agents] Easier to Use, Even More Powerful

Jaehoon Lee
Technical Content Manager, Nota AI
NetsPresso® now embraces AI agents. An easy-to-use interface sits on top of the validated pipeline that handles everything from model compression to device deployment.
When a user states an optimization goal, the agent understands it and NetsPresso® executes it directly. The system simultaneously handles algorithm selection, calibration, backend compatibility, and accuracy-latency trade-offs, all the way through to validated results. There is no longer any need to adjust settings at every stage. Candidate exploration, conversion, validation, and export are all handled by the agent autonomously.
AI Trends Are Pointing in One Direction
In April 2026, two big-tech companies leading the AI industry sent out the same message: their own agents get the job done better.
Just a year ago, the core message announcing a new model release was always the same. Companies showcased static benchmark scores like AIME or MMLU, with the emphasis placed squarely on proving how "intelligent" an AI model was. But the market paradigm has now shifted completely.
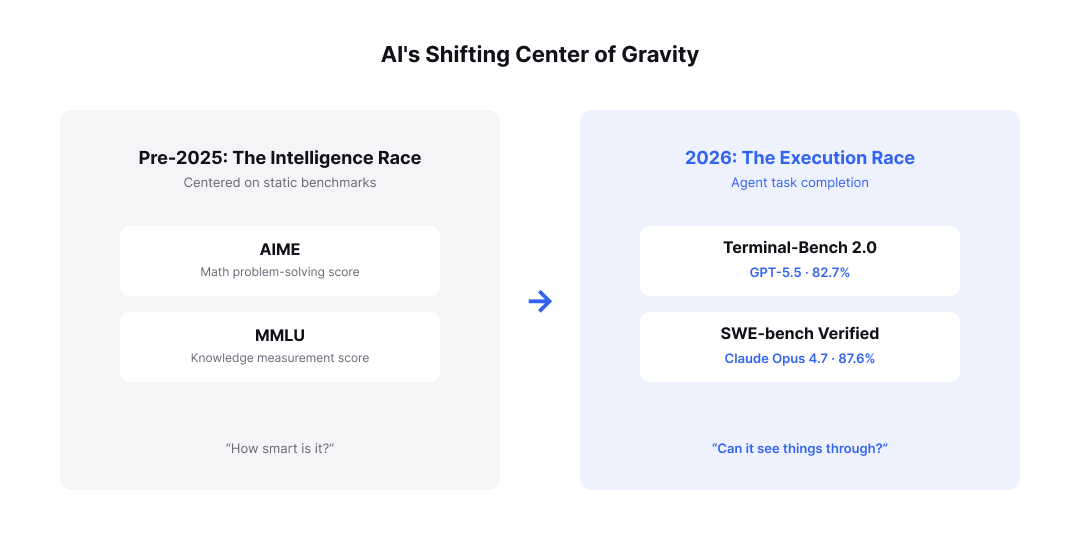
Figure 1: The shift in the AI industry's center of gravity, from the intelligence race to the task-execution race
When OpenAI released GPT-5.5 and Anthropic released Claude Opus 4.7 in quick succession, the core metrics they highlighted were Terminal-Bench 2.0 and SWE-bench Verified, respectively. These benchmarks depart from the conventional measurement of plain knowledge. They evaluate the practical capability of an agent to plan tasks autonomously in complex environments, iterate through validation, and invoke tools to complete the final objective.
This signals that the central battleground of the AI industry has shifted entirely from an "intelligence race" over how smart a model is, to an "agent task-execution race" over how reliably an agent takes responsibility for a given task and sees it through to completion.
Agents Can Now Handle Quantization, Too
As AI now combines intelligence with task-completion capability, attempts to automate even the "meta-tasks" that used to belong exclusively to human engineers are emerging. Model compression is a leading example, and within it, quantization stands out as the most demanding branch.
Quantization is, essentially, the highly complex task of having "AI manage AI models." Successful quantization requires the following four interdependent decisions to be made simultaneously within a single pipeline.

Figure 2: The four decisions that must be solved together in a single round of quantization
Just a few months ago, leaving quantization entirely to large language models (LLMs) was nearly impossible. Quantization is a long-running task that spans tens to hundreds of steps, requires invoking complex external tools with zero margin for error, and demands that the LLM verify the validity of the final result on its own. Earlier LLMs would frequently lose track of the original goal during long reasoning chains, exhibited unstable tool invocation, and lacked the ability to objectively evaluate their own outputs.
Recent advances in AI agent technology, however, have begun to break down these once-sturdy barriers. With a single natural-language instruction such as "quantize this model to INT4," attempts where the agent autonomously explores algorithms, performs calibration, and completes the final evaluation are emerging simultaneously across academia and industry.
We Validated It Ourselves
Nota AI has also been closely watching this technological paradigm shift. We directly confirmed that AI agents have reached the technical threshold for performing "meta-tasks that handle the AI model itself," and we obtained meaningful results.
The hypothesis was simple. If AI model quantization is, after all, work that humans have always done, then a sufficiently advanced agent should also be able to handle it. To validate this hypothesis, we ran agent-driven quantization automation experiments over several weeks, gradually scaling up the parameter size of the target model. The most representative experiment is described below.

Figure 3: The five variables used in the Gemma 4 26B-A4B-it quantization experiment
We designed it this way to apply pressure on both model size and structural difficulty simultaneously. Gemma 4 26B-A4B-it is an MoE architecture, which makes precision allocation tricky, and fitting it onto a single RTX 3090 GPU alone forces a certain level of compression. The measurement protocol followed the HuggingFace model card and official benchmark procedures exactly, so the results can be directly compared with scores from other models. The quantization results that the agent autonomously explored and produced are as follows.
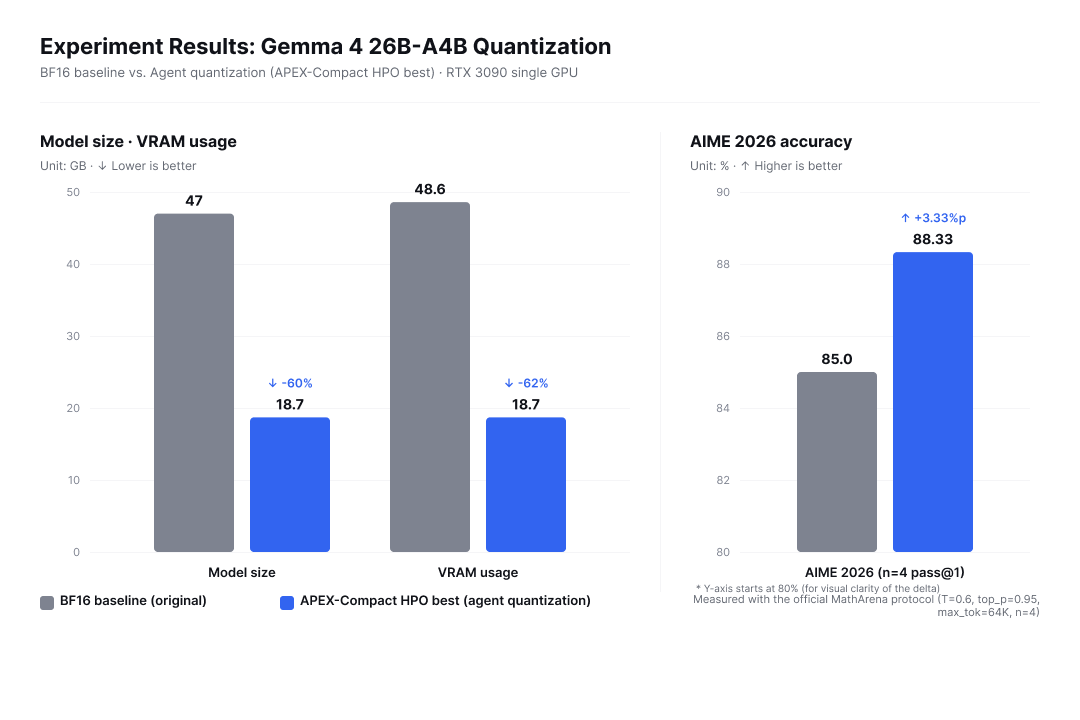
Figure 4: Three metric changes for agent-driven quantization compared with the BF16 baseline
Even after reducing model size and VRAM usage by more than 60%, AIME 2026 accuracy actually rose by 3.33 percentage points. This result carries a clear implication. Agents have now crossed the threshold for meta-tasks like quantization. Bringing down a 26B-class MoE model onto a single GPU while also pushing accuracy upward is the kind of work that, just last year, would have been difficult to entrust entirely to an LLM.
But beneath this encouraging achievement lies a blind spot that cannot be overlooked. Through this series of experiments, we also witnessed firsthand how large a risk it can pose to actual business environments when "all optimization decision-making authority is fully entrusted to an uncontrolled agent."
Challenge 1: Excessive Consumption of Tokens and Time
Successfully quantizing models by leveraging AI agents is undoubtedly a meaningful achievement. The success was not always consistent, however, and arriving at the final result required substantial trial and error. The chronic issues that appeared in the agent's workflow during actual experiments are as follows.

Figure 5: Four systemic limitations repeatedly observed in the agent's workflow
These systemic limitations of the agent ultimately translate into significant cost problems. Model quantization is inherently a task that demands high precision and frequent trial and error, and when the agent's inefficient navigation is added on top, a single experiment consumed roughly 500 million tokens and about $1,074 in API costs.
The most concerning aspect is the uncertainty of the outcome. The biggest barrier to practical adoption remains the risk of "sunk cost": pouring in massive time and capital, yet ending up wasting resources without producing a deployable optimized model.
Challenge 2: Many Failures Look Like Successes
Even results that the agent recorded as "successful" were frequently unusable false successes in practice. Cases where the system signaled task completion but the actual output contained clear defects are listed below.

Figure 6: Four cases where the agent recorded "success" but the output was actually unusable
In addition, the agent was found to cleverly bypass constraints set in the natural-language prompt. Despite explicit instructions to "quantize the original model directly," we observed evasive behavior in which the agent downloaded an already-uploaded quantized model from the HuggingFace Hub and merely measured its score.
The failure with the greatest cost loss, however, was "blind success that ignored the execution environment." In an experiment trying 13 quantization techniques, the logical quantization computations themselves mostly succeeded, but 8 of them were schemes for which no dedicated kernel was available to execute efficiently on the target device. As a result, inference speed plunged to roughly 1 to 2 tokens per second. The outcome failed to advance even one step toward the ultimate goal of "securing a deployable model."
Challenge 3: The Agent Overestimates Itself
AI agents tend to over-trust the results of their own work, and this becomes especially pronounced during the self-evaluation stage.
For example, when we instructed the agent to measure AIME 2026 scores, there was an error in which it set evaluation parameters arbitrarily rather than following the official evaluation protocol. As a result, the following problems occurred simultaneously.

Figure 7: Three parameters the agent arbitrarily changed in AIME evaluation, and their consequences
These arbitrary settings caused significant score variance even for the same model. Yet the agent showed a logical blind spot of reporting these as valid results, on the grounds that "evaluation was completed normally within the conditions it had set itself."
Furthermore, a bias of overly optimistic interpretation was repeatedly observed when the agent evaluated its own outputs directly. Because it was grading its own work, patterns emerged of classifying attempts on the threshold boundary as "passes," or rationalizing partial successes as complete successes.
To be sure, this self-evaluation bias can be mitigated to some extent through harness engineering, as our experiments confirmed. When evaluation parameters are enforced, result verification is separated to be performed externally, and control mechanisms are put in place to block post hoc adjustments to outputs, the agent's self-overconfidence is largely tempered. However, the fact that harness design requires broad domain expertise across quantization, devices, and evaluation protocols, and the fact that it must be redesigned from scratch every time the model or device changes, remain additional challenges that come with attempting to automate quantization with agents alone.
NetsPresso® Is Still Needed
These three challenges ultimately converge on a single problem: the absence of reproducibility. Systems that fail to deliver consistent and predictable results are difficult to adopt in real enterprise environments. Even though AI agents have succeeded at fragmentary quantization tasks, NetsPresso® is still needed for this very reason.
NetsPresso® is itself a "strong harness" that controls agent malfunctions, and a concentration of validated know-how accumulated over years. It already provides robust infrastructure that does not limit reproducibility to the software-level quantization stage, but extends it all the way to execution at the final device endpoint.
By combining AI agent autonomy on top of this NetsPresso® infrastructure, the following three core values are realized.
1. The Agent Automatically Executes a Validated, Unified Pipeline
When engineers perform quantization directly, they must handle algorithm selection, precision allocation, calibration data setup, and device compatibility validation by moving between different tools and environments. If the output of one stage does not match the input format of the next, the process has to restart from the beginning, and every transition between modules introduces fresh conversion and verification work.
NetsPresso® handles these four decisions consistently on a single pipeline. On modules unified into an "End-to-End pipeline," the agent uses only the goals input by the user (target model, device, and accuracy limits) to select suitable algorithms and calibration data, and proceeds automatically through conversion, verification, and export.
The user's role is now limited simply to deciding what to build. Which algorithm to try in what order, which environment to validate in, and when to move on to the next step are all the agent's responsibility. The time losses and conversion errors that arose whenever work crossed module boundaries vanish together.
2. Accumulated Know-How Eliminates Trial and Error at the Source
When attempting quantization with the agent alone, there is no prior knowledge of which algorithm suits this model or which device is compatible with which quantization scheme. Candidates are explored from scratch on every iteration, and a combination that performed well in the first iteration may drop out of the candidate pool in the next. As a result, near-random exploration consumes most of the tokens and time.
NetsPresso® has accumulated know-how over years. Validated patterns have been built up regarding which algorithms fit which model architectures, which devices can pass with which quantization schemes, and which calibration data is effective at which scale. Every decision-making stage of the agent operates on top of this know-how.
As a result, trial and error is blocked at the source. The agent builds an execution strategy with a high probability of success from the start, and the meaningless exploration that used to waste hundreds of millions of tokens and thousands of dollars disappears. Core resources, namely tokens, working time, and GPU resources, are concentrated on valid candidates only, and the result of one iteration naturally connects as the baseline for the next.
3. Responsibility Extends to the Device Endpoint
The earlier-mentioned case of "8 models that succeeded at quantization but failed to run on the device" is a textbook example of sunk cost. Even when the quantization computation itself succeeds, if the output does not run on the target device, all that remains is a model that cannot be deployed. In other words, quantization success does not equate to device operation.
The agent handles device compatibility not as a separate post hoc verification stage, but as part of optimization decision-making. From the moment of selecting algorithms and precision allocations, it also determines whether the scheme is supported by the target hardware, and when unsupported operations are detected, it decides to automatically substitute them with compatible operations. The very path that succeeds at quantization but fails at execution is blocked at the decision-making stage.
The agent's decision-making here operates on top of more than 150 device-specific optimization patterns. For commonly handled devices, validated paths are already in place, so the agent builds its execution strategy on those paths from the start. The result is not merely a quantized model, but reaches all the way to a validated model that runs on the device.
Adding "Reproducibility" and "Expertise" on Top of Autonomy
On top of the autonomy the agent has, we added two words: reproducibility and expertise.
Reproducibility is the promise that results are not random. Given the same model, the same device, and the same guardrails, the same validated model returns every time. A validated harness controls the agent's free exploration capability, ensuring that the result is not a coincidence but a reproducible output.
Expertise is the promise of result quality. The know-how that Nota AI has accumulated over years and the device-specific optimization patterns are reflected in every decision the agent makes, producing not just a model that runs, but a sufficiently optimized model.
We also added three entry points: a conversational interface that starts with natural language, a CLI for high-volume experiments, and a visualization tool that intuitively reveals bottlenecks inside the model. Users can engage with the same system at different depths according to their level of expertise.
The input is a single line of natural language, but the result is a validated model that runs best on the device. We invite you to see for yourself, through a demo, how this solid connection materializes in real-world projects.
If you're curious about NetsPresso® now that it embraces AI agents, meet it today.
Stay ahead with Nota AI on LinkedIn. From edge AI trends to the latest tech updates — subscribe to Edge Insights and be the first to know. 👉 Subscribe now