NVIDIA Blackwell; The Impact of NVFP4 For LLM Inference

Seungmin Yang
EdgeFM Lead, Nota AI
Summary
With the introduction of NVFP4—a new 4-bit floating point data type in NVIDIA’s Blackwell GPU architecture—LLM inference achieves markedly improved efficiency.
Blackwell’s NVFP4 format (RTX PRO 6000) delivers up to 2× higher LLM inference efficiency compared with NVIDIA A100 with negligible accuracy loss, proving ultra-low-precision computation can be both practical and reliable.
There remains room for further model compression and optimization through techniques unique to the Blackwell architecture and extension to the multi-modality.
Introduction
In March 2024, NVIDIA announced Blackwell—its next GPU architecture—bringing a major update to the 5th-generation Tensor Cores, which now natively support FP4 (and FP6) for ultra-low-precision AI operation. This post focuses only on NVFP4, NVIDIA’s FP4 data format for Blackwell. (Blackwell also introduces “Tensor Memory,” a new on-chip memory tier that changes GEMM kernels, but that’s out of scope here)
Why does NVFP4 matter?
Classic FP4 squeezes each value into 4 bits—great for bandwidth and compute—but risks accuracy. NVFP4 tackles that tradeoff with micro-block scaling. With this technique, values are grouped into blocks of 16, each sharing a high-precision FP8 (E4M3) scaling factor, plus an additional per-tensor FP32 scale. In practice, each 4-bit number is a tiny index and the scale is the “zoom level” that restores magnitude during compute;
This approach is simpler yet more effective than existing methods like DoRA (uses object tracking) and PooDLe (uses optical flow). The proposed model achieves 36.4% mIoU on ADE20K and 33.5 mAP on COCO, surpassing current state-of-the-art performance.

where:
xFP4quantized : a 4-bit quantized value in E2M1 format (1 sign bit, 2 exponent bits, 1 mantissa bit) — very compact but low precision.
SFP8block : an FP8 (E4M3) block-wise scale, shared across 16 consecutive FP4 values, providing a local zoom factor that restores relative magnitudes.
SFP32tensor : a per-tensor FP32 scale, applied once per tensor to keep all block scales within a stable range.
This two-level scheme preserves dynamic range and reduces quantization error while keeping the data tiny—exactly what large Transformer-based LLMs need at inference.
What is evaluated in this post?
Motivated by the hardware FP4 path and NVFP4’s layout, I measure LLM inference on a Blackwell workstation GPU, the RTX PRO 6000, and share where NVFP4 helps most (and where it needs care). The RTX PRO 6000 is a Blackwell-class pro GPU with 5th-gen Tensor Cores and 96 GB GDDR7, making it a practical target for On-Premise LLM serving.
Experiment Setup
Framework & Data

Target Devices

Efficiency Metrics

Accuracy Benchmarks

Quantization Variants

Experimental Results
Efficiency
Since the Y-axis scales differ across panels (e.g., 3.0 s vs 2.0 s), cross-device absolute comparisons should be avoided; the focus here is on relative performance within each GPU.
TTFT (Prefill Phase)
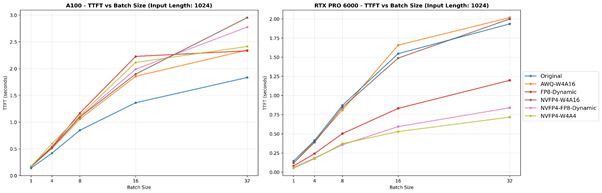
TTFT-Batch size graph with fixed input token length (1024). The figure on the left side is results on A100 and right side is that on RTX PRO 6000.

TTFT-Input Token Length graph with fixed batch size (16). The figure on the left side is results on A100 and right side is that on RTX PRO 6000.
On A100 (Ampere), the Original (BF16) model achieves the lowest TTFT across all conditions. This is expected since A100’s Tensor Cores natively support FP16/BF16 as their highest-throughput compute path (~312 TFLOPS dense, 624 TFLOPS sparse[2]). FP8 and FP4 operations, on the other hand, are not natively supported on Ampere — they are emulated through higher-precision kernels,resulting in no latency advantage compared with BF16.
On RTX PRO 6000 (Blackwell), NVFP4-W4A4 consistently delivers the fastest TTFT, followed by NVFP4-FP8-Dynamic. Blackwell’s 5th-generation Tensor Cores natively support FP4/FP6/FP8, allowing NVFP4 workloads to fully utilize low-precision compute and bandwidth efficiency. As batch size or input sequence length grows, the matrix-multiply load and memory pressure increase, amplifying the benefits of native FP4 execution. This demonstrates Blackwell’s strong prefill-phase efficiency compared with earlier architectures.
However, it is important to note that software and kernel maturity (e.g., vLLM runtime and NVFP4/FP8 kernel implementations) can affect the absolute margins shown here. As frameworks and kernels evolve, absolute TTFT values and relative gaps may shift, so these results should be interpreted as relative trends based on vLLM v0.10.1.1.
TPOT (Decode Phase)

TPOT-Batch size graph with fixed input token length (1024). The figure on the left side is results on A100 and right side is that on RTX PRO 6000.

TPOT-Input Token Length graph with fixed batch size (16). The figure on the left side is results on A100 and right side is that on RTX PRO 6000.
Across both GPUs, a consistent trend emerges: the lower the numerical precision, the smaller the TPOT (Time-Per-Output-Token). This reflects the inherent nature of the decode phase, where the introduction of the Key–Value (KV) cache reduces the computational weight of matrix multiplications per token, shifting the dominant bottleneck from computation to memory access. As a result, formats that minimize data movement make more efficient use of available memory bandwidth, producing shorter latency per token.
When comparing the two devices, A100 (Ampere) generally shows lower TPOT than RTX PRO 6000 (Blackwell) across most conditions. This is primarily due to the A100’s higher memory bandwidth (≈2,039 GB/s via HBM2e) compared to the RTX PRO’s GDDR7 bandwidth (≈1,792 GB/s), which provides a clear advantage in a memory-bound scenario. However, as the input length or batch size increases, the workload transitions from memory-bound to compute-bound. In this regime, Blackwell’s native FP4/FP8 Tensor Core pathways begin to show their strength, leading to cross-over points where NVFP4-based models surpass higher-precision ones—similar to the pattern observed in the prefill phase.
An intriguing observation is that on RTX PRO 6000, not only AWQ-W4A16 but also NVFP4-W4A16 achieves lower TPOT than fully lower-bit NVFP4 variants such as NVFP4-FP8-Dynamic and NVFP4-W4A4. In the case of AWQ, this can be readily explained by the use of the specialized AWQ-Marlin kernel, which is explicitly beneficial for small/moderate-batch decode workloads, reducing launch overhead and improving scheduling and memory reuse. For NVFP4-W4A16, however, the explanation lies elsewhere: although it lacks a Marlin-style kernel, it compresses only the weights into FP4 while retaining FP16 activations. This allows it to execute on the mature FP16 accumulation path with well-optimized GEMM kernels. In contrast, FP4/FP8 kernels—while natively supported on Blackwell—remain in relatively early stages of optimization within vLLM and CUTLASS. These kernels can incur non-negligible overhead from block-scale application and dequantization steps. Furthermore, since decoding is dominated by KV-cache activation reads rather than repeated weight matmuls, the advantage of fully quantized activations becomes limited, and the extra dequantization operations may even offset their theoretical gains. Consequently, NVFP4-W4A16 can outperform fully lower-bit NVFP4 configurations in practical latency measurements under current software conditions.
Throughput (Overall)

Throughput-Batch size graph with fixed input token length (1024). Solid lines indicate best cases for RTX PRO 6000 and dot lines means best cases for A100.
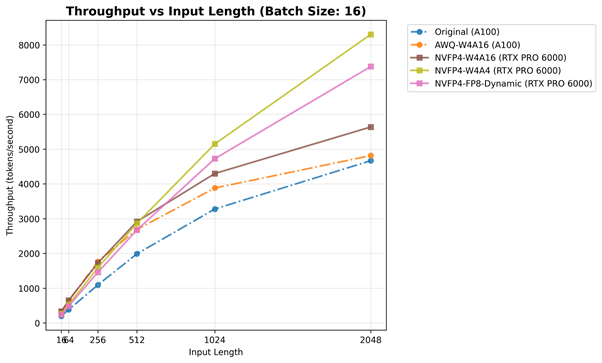
Throughput-Input Token Length graph with fixed batch size (16). Solid lines indicate best cases for RTX PRO 6000 and dot lines means best cases for A100.
Building on the findings from the Prefill (TTFT) and Decode (TPOT) phases, the throughput results can be seen as a summary metric that unifies both behaviors. While TTFT reflects the latency of reading and processing the input prompt, and TPOT captures the per-token generation efficiency, throughput represents the overall capability of the inference pipeline as a whole. For small batches, kernel launch and memory latency dominate, but as the workload increases, those effects diminish, and the hardware operates closer to its true throughput limit.
On the A100 (Ampere), both Original (BF16) and AWQ-W4A16 configurations show steady but moderate scaling, reaching around 4,000–5,000 tokens/sec. As discussed in TTFT/TPOT analyses, this reflects the lack of native FP4/FP8 execution on Ampere — the GPU simply cannot fully exploit the benefits of ultra-low-bit computation, and its FP16/BF16 path remains the most optimized and efficient.
In contrast, the RTX PRO 6000 (Blackwell) demonstrates clear superiority. All NVFP4-based models outperform the A100 across the board, with NVFP4-W4A4 and NVFP4-FP8-Dynamic reaching 6,000–8,000 tokens/sec, roughly 1.7–2× higher throughput than A100 under identical conditions. This outcome directly mirrors our earlier phase analyses: the Prefill advantages of native FP4/FP8 computation combine with the Decode-phase memory efficiency to produce large end-to-end gains. In short, Blackwell’s 5th-generation Tensor Cores natively accelerate FP4/FP8 math, drastically increasing arithmetic density.
Between the NVFP4 variants, NVFP4-FP8-Dynamic overtakes NVFP4-W4A16 as batch size or input length grows, because quantizing activations to FP8 significantly reduces memory traffic and scaling overhead becomes negligible in large compute-bound workloads. However, in smaller batches, the dynamic-scaling cost can offset those benefits, making NVFP4-W4A16 slightly more efficient.
Through the experiments, Blackwell scales its performance consistently with workload size, showing that its low-precision NVFP4 format delivers a truly scalable inference throughput. Together, these results confirm that the combination of Blackwell architecture and NVFP4 quantization unlocks sustained efficiency across the entire inference pipeline, offering a decisive advantage for next-generation LLM workloads.
Accuracy
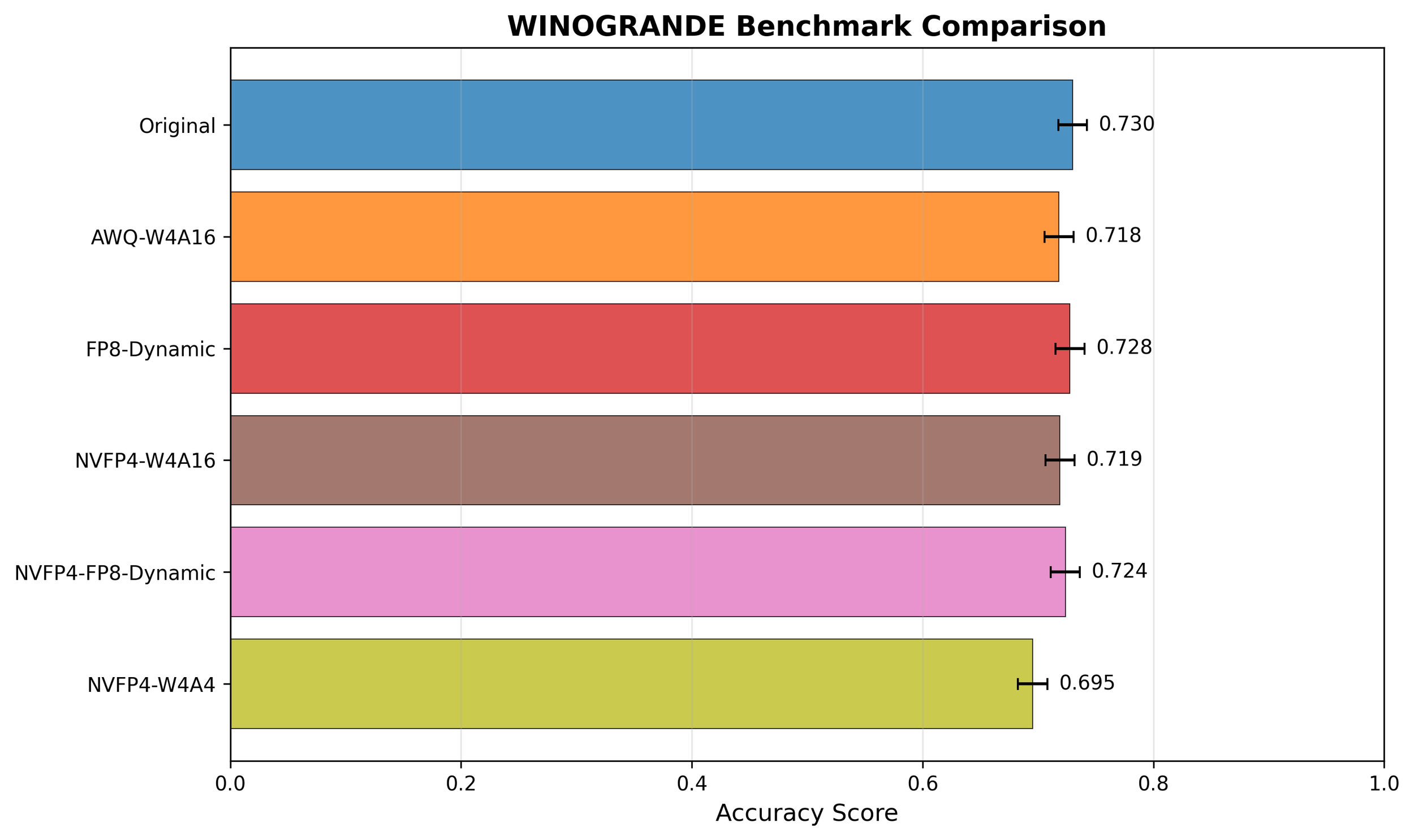
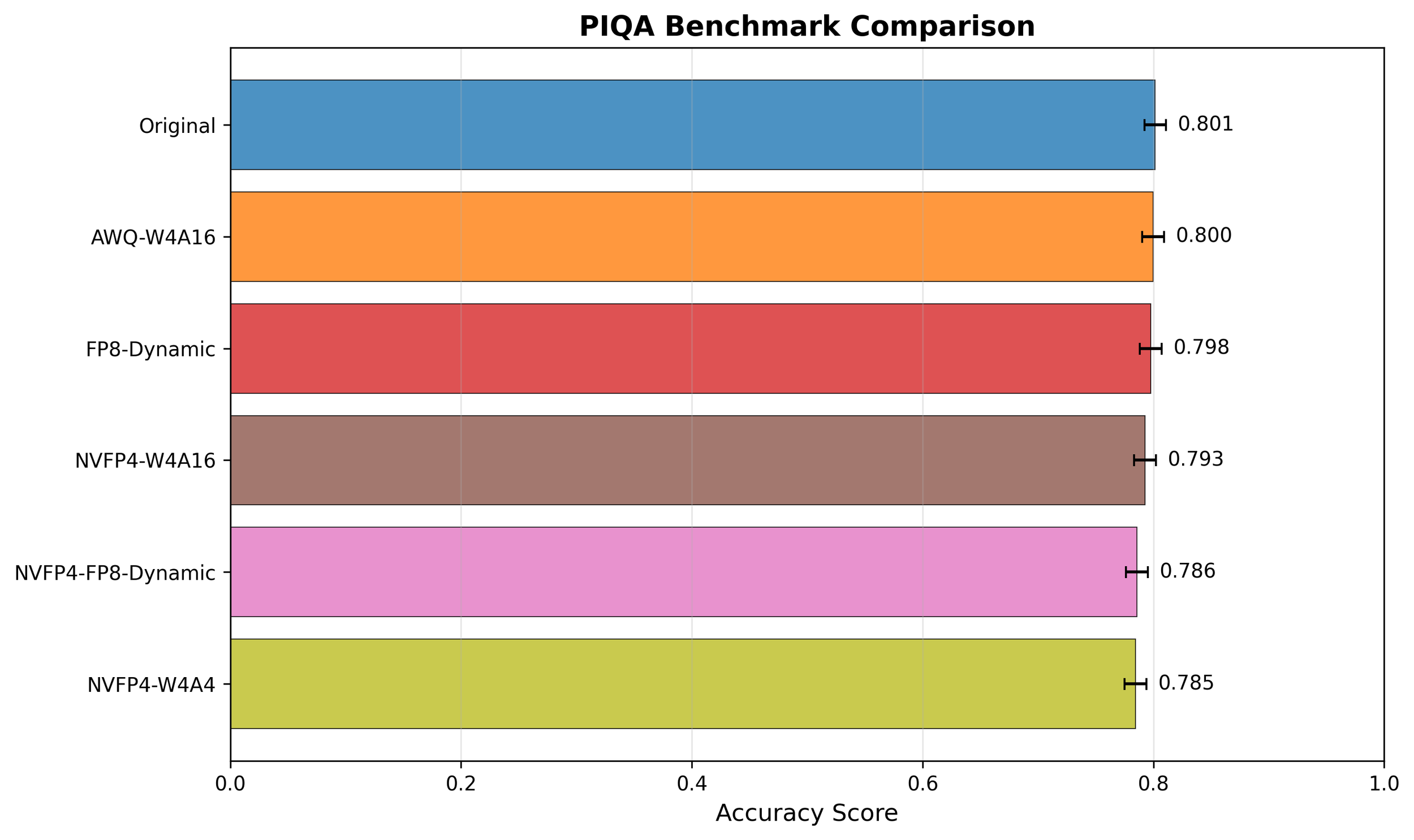
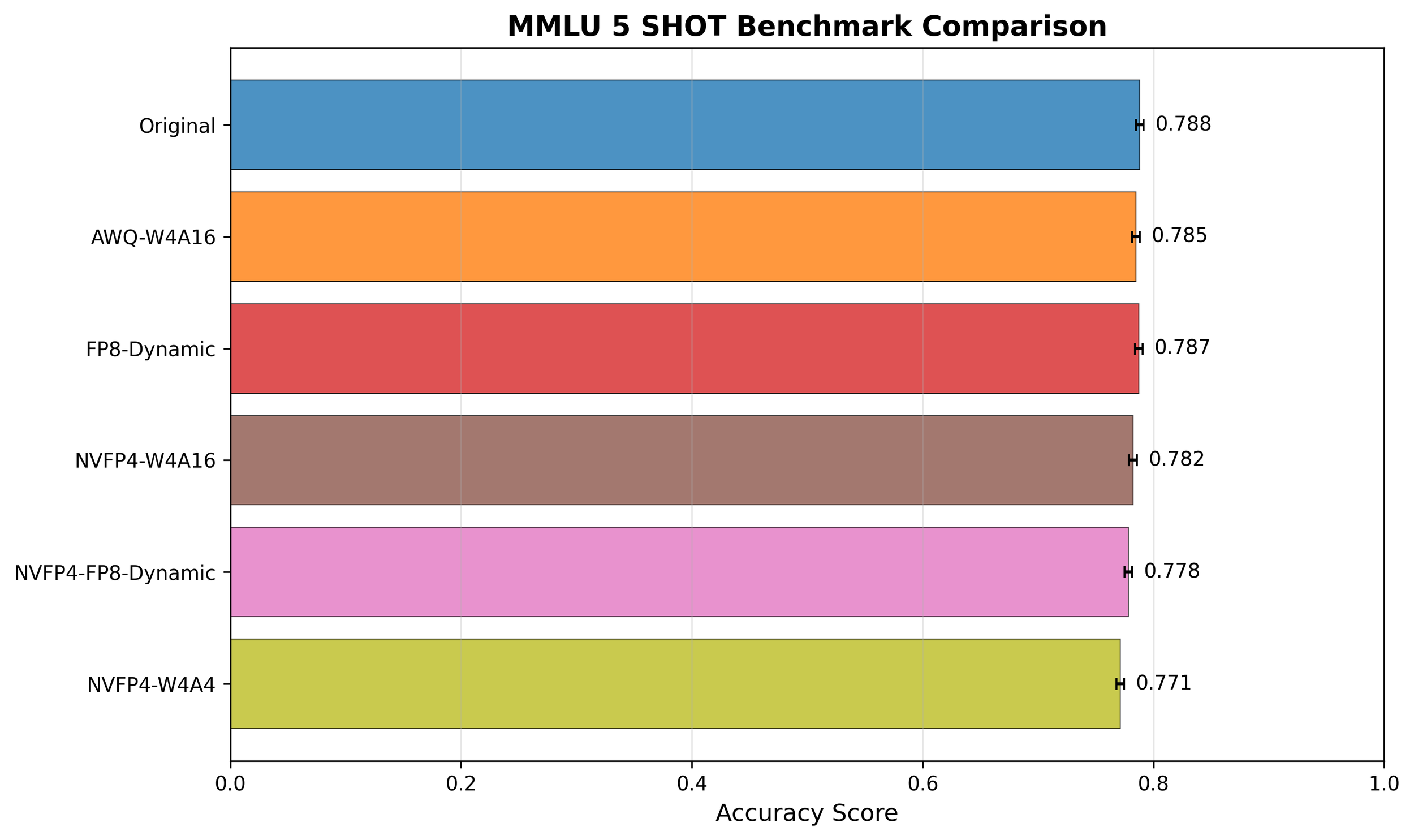

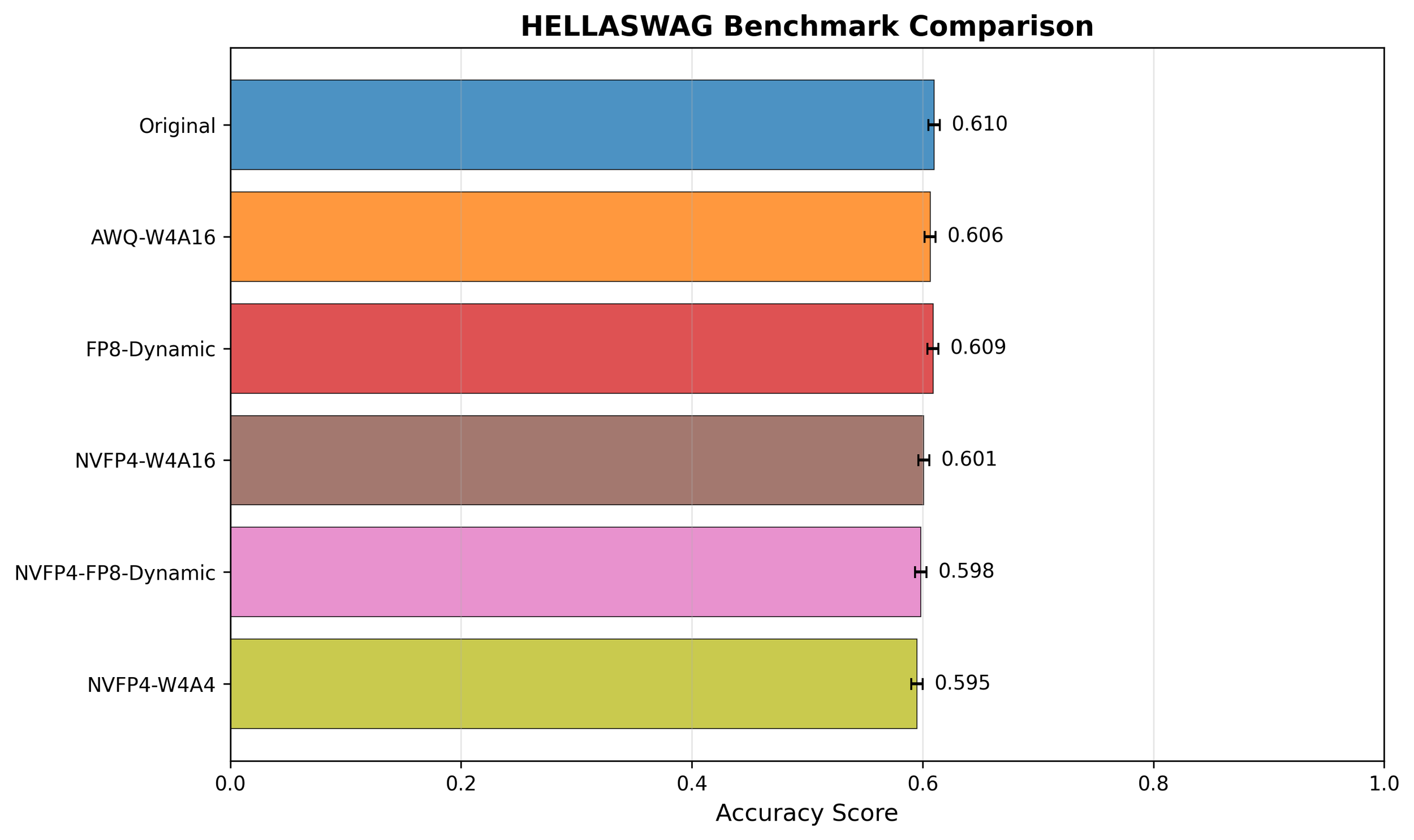
The academic benchmark results complement the latency and throughput analyses by revealing how quantization affects model quality in practice. Across HellaSwag, MMLU, and PiQA, accuracy differences among all precision formats are within ±0.005–0.02, effectively negligible both statistically and practically. Such small variations can easily arise from non-deterministic factors such as random seeds, prompt ordering, or tokenization details.
These findings are consistent with prior literatures which are most practical nowadays. Lin et al.[3] showed that 4-bit AWQ quantization preserves `near-lossless` (0.1-0.7 score drop) performance; Xiao et al.[4] reported <0.3% deviation after 4-bit/8-bit quantization; This confirms that Blackwell’s NVFP4 format achieves up to 2× higher efficiency while maintaining near-lossless accuracy compared to FP16/BF16 baselines.
Only Winogrande shows a slightly larger variation, likely due to its linguistic reasoning complexity. Winogrande evaluates commonsense pronoun resolution—one of the most semantically sensitive benchmarks—where small precision perturbations can directly alter contextual understanding. Its relatively small dataset size and sentence diversity also make accuracy more volatile, amplifying minor numerical effects. Hence, these deviations should be interpreted as task-level sensitivity rather than genuine model degradation.
That said, the benchmarks used here are not fully representative of real-world LLM deployment scenarios. While HellaSwag, MMLU, PiQA, and Winogrande capture general reasoning and commonsense tasks, they do not comprehensively cover large-scale knowledge retrieval, multi-turn dialogue, coding, or mathematical reasoning. Still, it is remarkable that NVFP4 maintains almost lossless accuracy even under such an extremely low-bit (FP4) setting, and this suggests strong potential for further optimization—for instance, through better scaling strategies, calibration sets, or structure-aware quantization—to make NVFP4-based compression virtually lossless in practice.
Conclusion
This experiment demonstrated that Blackwell’s architecture and the NVFP4 data format can dramatically improve LLM inference efficiency. Native FP4 computation in the prefill phase and enhanced memory efficiency during decode together achieved up to 2× higher throughput compared to A100 (Ampere), while accuracy degradation remained statistically insignificant. These results confirm that NVFP4 delivers the practical benefits of ultra-low-precision computation without compromising FP16/BF16-level quality. This indicates that low-precision arithmetic is not merely an optimization trick but a viable acceleration technology for large-scale language model inference, offering a clear path toward improved efficiency and cost-effectiveness.
Nota has already been actively developing Vision-Language Model (VLM)–based solutions and will extend the findings of this study to optimize NVFP4 inference for multimodal workloads. Because visual features are generally more continuous and densely distributed than textual ones, more nuanced optimization is required.
(1) researching quantization techniques specialized for multimodal architectures
(2) developing NVFP4-optimized GEMM/GEMV compute kernels and scheduling methods
(3) conducting analysis and specialized optimization studies of the Tensor Memory hierarchy, which was not explored in this work
With these possible future works, Nota will lead the way to real-time, high-efficiency inference for next-generation large-scale models.
References
[1]https://www.nvidia.com/content/dam/en-zz/Solutions/design-visualization/quadro-product-literature/workstation-datasheet-blackwell-rtx-pro6000-x-nvidia-us-3519208-web.pdf
[2]https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet-us-nvidia-1758950-r4-web.pdf
[3]Lin, Ji, et al. "Awq: Activation-aware weight quantization for on-device llm compression and acceleration." Proceedings of machine learning and systems 6 (2024): 87-100.
[4]Xiao, Guangxuan, et al. "Smoothquant: Accurate and efficient post-training quantization for large language models." International conference on machine learning. PMLR, 2023.
If you have any further inquiries about this research, please feel free to reach out to us at following 📧 email address: contact@nota.ai.
Furthermore, if you have an interest in AI optimization technologies, you can visit our website at 🔗 netspresso.ai.